SQL
To view this content, buy the book! 😃🙏
Or if you’ve already purchased.
SQL
Background: SQL
Contents:
In this section we replace our use of MongoDB with SQL. In the first part we’ll get our SQL database and table schemas set up. Then we’ll replace our use of MongoDataSource with SQLDataSource. Then in SQL testing, we update our tests, and, finally in SQL performance, we improve our server’s database querying.
SQL setup
If you’re jumping in here,
git checkout 25_0.2.0(tag 25_0.2.0, or compare 25...sql)
A SQL database takes more setup than the MongoDB database we’ve been using: We need to write migrations—code that creates or alters tables and their schemas. The most popular Node library for SQL is Knex, and it includes the ability to write and run migrations. To start using it, we run knex init. Since we already have it in our node_modules/, we can run npx knex init in a new directory within our repository:
$ mkdir sql
$ cd sql/
$ npx knex initThis creates a config file:
// Update with your config settings.
module.exports = {
development: {
client: 'sqlite3',
connection: {
filename: './dev.sqlite3'
}
},
staging: {
client: 'postgresql',
connection: {
database: 'my_db',
user: 'username',
password: 'password'
},
pool: {
min: 2,
max: 10
},
migrations: {
tableName: 'knex_migrations'
}
},
production: {
client: 'postgresql',
...
}
}By default, it uses SQLite and PostgreSQL (two types of SQL databases) for development and deployment, respectively.
One aspect of database setup that’s easier with SQL than MongoDB is running the database in development—SQLite doesn’t need to be installed with Homebrew and run as a service. Instead, it can be installed with a Node library and run off of a single file. So unless we’re using a special feature that PostgreSQL supports but SQLite doesn’t, we can use SQLite in development.
We also won’t be deploying, so all we need is:
module.exports = {
development: {
client: 'sqlite3',
connection: {
filename: './dev.sqlite3'
},
useNullAsDefault: true
}
}(We added useNullAsDefault: true to avoid a warning message.)
Now we can use Knex to create a migration that will set up our users and reviews tables:
$ npx knex migrate:make users_and_reviewsThis generates a file in the following format:
sql/migrations/[timestamp]_users_and_reviews.js
exports.up = function(knex) {
}
exports.down = function(knex) {
}Inside the up function, we create the two tables, and inside the down function, we drop (delete) them. To do all that, we use Knex’s schema-building API:
sql/migrations/20191228233250_users_and_reviews.js
exports.up = async knex => {
await knex.schema.createTable('users', table => {
table.increments('id')
table.string('first_name').notNullable()
table.string('last_name').notNullable()
table.string('username').notNullable()
table.string('email')
table
.string('auth_id')
.notNullable()
.unique()
table.datetime('suspended_at')
table.datetime('deleted_at')
table.integer('duration_in_days')
table.timestamps()
})
}knex.schema.createTable('users'creates a table namedusers.table.increments('id')creates a primary index column namedid. It’s auto-incrementing, which means the first record that’s inserted is given anidof 1, and the second record gets anidof 2, etc.table.string('first_name').notNullable()creates afirst_namecolumn that can hold a string and can’t be null.table.string('auth_id').notNullable().unique()creates anauth_idnon-nullable string column that has to be unique among all records in the table.table.datetime('suspended_at')creates asuspended_atcolumn that can hold a datetime.table.timestamps()createscreated_atandupdated_atdatetime columns.
Similarly, we can create the reviews table:
exports.up = async knex => {
await knex.schema.createTable('users', table => { ... })
await knex.schema.createTable('reviews', table => {
table.increments('id')
table
.integer('author_id')
.unsigned()
.notNullable()
.references('id')
.inTable('users')
table.string('text').notNullable()
table.integer('stars').unsigned()
table.timestamps()
})
}The below part sets up a foreign key constraint on author_id, so the only values that can be stored in this column match an id field in the users table:
table
.integer('author_id')
.unsigned()
.notNullable()
.references('id')
.inTable('users')Finally, we call dropTable() in the down function:
sql/migrations/20191228233250_users_and_reviews.js
exports.up = async knex => {
await knex.schema.createTable('users', table => { ... })
await knex.schema.createTable('reviews', table => { ... })
}
exports.down = async knex => {
await knex.schema.dropTable('users')
await knex.schema.dropTable('reviews')
}To run our migration up function, we use:
$ npx knex migrate:latestAnd to undo, we would do npx knex migrate:rollback --all. If in the future we want to make a change to the schema, we would create another migration with a more recent timestamp—e.g., [timestamp]_add_deleted_column_to_reviews.js—that adds a deleted column to the reviews table, and commits it to git. Then, whenever a dev was on the version of the code that used the reviews.deleted column, they could migrate to the latest version of the database, and code that modifies a review’s deleted field would work.
With MongoDB, we didn’t have migrations, and we added or changed documents manually. With SQL, we could run migrations that drop our tables and everything in them, so re-inserting records manually would get tedious. So Knex supports seed files that we can run to automatically insert records. We start with seed:make, which creates an example seed file:
$ npx knex seed:make usersexports.seed = function(knex) {
// Deletes ALL existing entries
return knex('table_name').del()
.then(function () {
// Inserts seed entries
return knex('table_name').insert([
{id: 1, colName: 'rowValue1'},
{id: 2, colName: 'rowValue2'},
{id: 3, colName: 'rowValue3'}
]);
});
};Now we modify the example file to use async/await and match our users table schema:
exports.seed = async knex => {
await knex('users').del()
await knex('users').insert([
{
id: 1,
firstName: 'John',
lastName: 'Resig',
username: 'jeresig',
email: '[email protected]',
authId: 'github|1615',
created_at: new Date(),
updated_at: new Date()
}
])
}And then copy the file for inserting reviews:
exports.seed = async knex => {
await knex('reviews').del()
await knex('reviews').insert([
{
id: 1,
author_id: 1,
text: `Now that's a downtown job!`,
stars: 5,
created_at: new Date(),
updated_at: new Date()
},
{
id: 2,
author_id: 1,
text: 'Passable',
stars: 3,
created_at: new Date(),
updated_at: new Date()
}
])
}We run the seed files with:
$ npx knex seed:runWe can view if it worked with either the command-line SQLite client or a GUI. The command-line client, sqlite3, is included by default on Macs. We give it the database file sql/dev.sqlite3 as an argument, and then we can run SQL statements like SELECT * FROM reviews;.
$ sqlite3 sql/dev.sqlite3
SQLite version 3.30.1 2019-10-10 20:19:45
Enter ".help" for usage hints.
sqlite> SELECT * FROM reviews;
1|1|Now that's a downtown job!|5|1578122461308|1578122461308
2|1|Passable|3|1578122461308|1578122461308There are many SQL GUIs. Our favorite is TablePlus, which works with not only different types of SQL databases, but other databases as well, including Redis and MongoDB. When creating a new connection, we select SQLite and then the file sql/dev.sqlite3, and hit Connect. Then on the left, we see the list of tables in our database, and if we double-click reviews, we see the table’s contents:
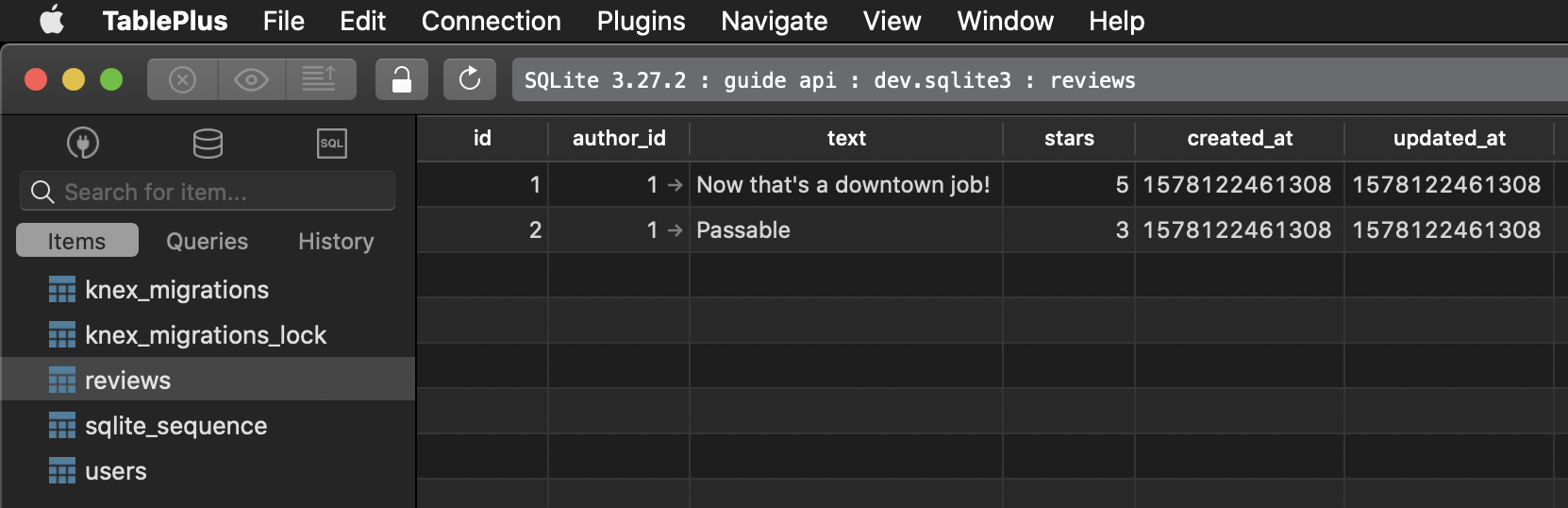
Lastly, we no longer need to connect to a MongoDB database, so we can remove the call to connectToDB() in src/index.js.
Before we commit our changes, we want to add the below line to .gitignore:
sql/dev.sqlite3We don’t want our database in our code repository—it’s meant to be generated and modified by each individual developer using our migration and seed scripts.
SQL data source
If you’re jumping in here,
git checkout sql_0.2.0(tag sql_0.2.0, or compare sql...sql2)
Now that we’ve set up our SQL database and inserted records, we need to query them. So we look for a SQL data source class to use, either on the community data sources list in the Apollo docs or by searching “apollo data source sql” on Google or npm. We find datasource-sql, which provides the class SQLDataSource.
SQLDataSource is unusual among data sources in that:
- A single instance is created (versus a new instance for each request).
- It does caching only, not batching.
It also:
- recommends using a single class for the whole database, instead of a class per table as we did with
MongoDataSource - uses a specific library—Knex!
Let’s start by creating our data source class:
import { SQLDataSource } from 'datasource-sql'
class SQL extends SQLDataSource {
// TODO
}
export default SQLOur job will be to fill in the class with methods our resolvers need. To know what those methods are, let’s go at it from the other direction: creating and using the data source as if it were complete.
First let’s create it. Instead of our current data sources file:
import Reviews from './Reviews'
import Users from './Users'
import Github from './Github'
import { db } from '../db'
export default () => ({
reviews: new Reviews(db.collection('reviews')),
users: new Users(db.collection('users'))
})
export { Reviews, Users, Github }we do:
import Github from './Github'
import SQL from './SQL'
export const knexConfig = {
client: 'sqlite3',
connection: {
filename: './sql/dev.sqlite3'
},
useNullAsDefault: true
}
export const db = new SQL(knexConfig)
export default () => ({ db })
export { Github }The SQLDataSource constructor takes the same config we have in our sql/knexfile.js. Since we only want a single instance, we move the creation (new SQL(knexConfig)) outside of the exported function. Instead of the data source instances being named reviews and users, it’s named db (because it is the way to access the whole SQL database).
Now in resolvers, we can use functions like context.dataSources.db.getReviews() instead of context.dataSources.reviews.all(). And we also need to replace camelCase fields with snake_case, like deletedAt -> deleted_at.
export default {
Query: {
me: ...,
user: (_, { id }, { dataSources: { db } }) => db.getUser({ id }),
searchUsers: (_, { term }, { dataSources: { db } }) => db.searchUsers(term)
},
UserResult: {
__resolveType: result => {
if (result.deleted_at) {
return 'DeletedUser'
} else if (result.suspended_at) {
return 'SuspendedUser'
} else {
return 'User'
}
}
},
SuspendedUser: {
daysLeft: user => {
const end = addDays(user.suspended_at, user.duration_in_days)
return differenceInDays(end, new Date())
}
},
User: {
firstName: user => user.first_name,
lastName: user => user.last_name,
email: ...,
photo(user) {
// user.auth_id: 'github|1615'
const githubId = user.auth_id.split('|')[1]
return `https://avatars.githubusercontent.com/u/${githubId}`
},
createdAt: user => user.created_at,
updatedAt: user => user.updated_at
},
Mutation: {
createUser(_, { user, secretKey }, { dataSources: { db } }) {
if (secretKey !== process.env.SECRET_KEY) {
throw new AuthenticationError('wrong secretKey')
}
return db.createUser(user)
}
}
}So the db.* methods we needed and named are:
db.getUser()
db.searchUsers()
db.createUser()Note that we needed to add resolvers for firstName, lastName, and updatedAt, because we no longer have database fields with those exact names (instead we have first_name, last_name, and updated_at).
Next let’s update our Review resolvers:
export default {
Query: {
reviews: (_, __, { dataSources: { db } }) => db.getReviews()
},
Review: {
author: (review, _, { dataSources: { db } }) =>
db.getUser({ id: review.author_id }),
fullReview: async (review, _, { dataSources: { db } }) => {
const author = await db.getUser({ id: review.author_id })
return `${author.first_name} ${author.last_name} gave ${review.stars} stars, saying: "${review.text}"`
},
createdAt: review => review.created_at,
updatedAt: review => review.updated_at
},
Mutation: {
createReview: (_, { review }, { dataSources: { db }, user }) => {
...
const newReview = db.createReview(review)
pubsub.publish('reviewCreated', {
reviewCreated: newReview
})
return newReview
}
},
Subscription: {
reviewCreated: ...
}
}We reused the db.getUser() function and used two new ones:
db.getReviews()
db.createReview()The Users and Reviews resolvers were the only place we used context.dataSources, but we can do a workspace text search for db.collection to find any other uses of our MongoDB database. The only match is from our context function in src/context.js:
const user = await db.collection('users').findOne({ authId })To update this, we need access to our SQL data source. In src/data-sources/index.js, we have this line:
export const db = new SQL(knexConfig)So we can import our new db from there.
import { db } from './data-sources/'
export default async ({ req }) => {
...
const user = await db.getUser({ auth_id: authId })
...
return context
}Now we can implement all the data source methods we’re using:
db.getReviews()
db.createReview()
db.createUser()
db.getUser()
db.searchUsers()Inside methods we have access to this.context, which has the current user, and this.knex, our Knex instance, which we use to construct SQL statements. For example, here’s SELECT * FROM reviews;:
import { SQLDataSource } from 'datasource-sql'
const REVIEW_TTL = 60 // minute
class SQL extends SQLDataSource {
getReviews() {
return this.knex
.select('*')
.from('reviews')
.cache(REVIEW_TTL)
}
async createReview(review) { ... }
async createUser(user) { ... }
async getUser(where) { ... }
searchUsers(term) { ... }
}
export default SQLThe added .cache() tells SQLDataSource to cache the response for the provided number of seconds.
Next up is createReview(), where we get a review from the client and need to add the current user’s ID as well as timestamps:
class SQL extends SQLDataSource {
getReviews() { ... }
async createReview(review) {
review.author_id = this.context.user.id
review.created_at = Date.now()
review.updated_at = Date.now()
const [id] = await this.knex
.returning('id')
.insert(review)
.into('reviews')
review.id = id
return review
}
async createUser(user) { ... }
async getUser(where) { ... }
searchUsers(term) { ... }
}We tell Knex to return the inserted ID (.returning('id')) so that we can add it to the review object and return it. We didn’t do this before because MongoDB’s collection.insertOne(review) automatically added an _id to review. We do the same for createUser():
class SQL extends SQLDataSource {
getReviews() { ... }
async createReview() { ... }
async createUser(user) {
const newUser = {
first_name: user.firstName,
last_name: user.lastName,
username: user.username,
email: user.email,
auth_id: user.authId,
created_at: Date.now(),
updated_at: Date.now()
}
const [id] = await this.knex
.returning('id')
.insert(newUser)
.into('users')
newUser.id = id
return newUser
}
async getUser(where) { ... }
searchUsers(term) { ... }
}Here we just take the fields out of the user argument (which matches the GraphQL schema) and put them into a newUser object that matches the SQL users table schema.
Lastly, we have getUser() and searchUser(). The getUser() function receives an object like {id: 1} or {auth_id: 'github|1615'}, which can be passed directly to Knex’s .where():
const REVIEW_TTL = 60 // minute
const USER_TTL = 60 * 60 // hour
class SQL extends SQLDataSource {
getReviews() { ... }
async createReview(review) { ... }
async createUser(user) { ... }
async getUser(where) {
const [user] = await this.knex
.select('*')
.from('users')
.where(where)
.cache(USER_TTL)
return user
}
searchUsers(term) {
return this.knex
.select('*')
.from('users')
.where('first_name', 'like', `%${term}%`)
.orWhere('last_name', 'like', `%${term}%`)
.orWhere('username', 'like', `%${term}%`)
.cache(USER_TTL)
}
}We use a longer TTL for users with the idea they’ll change less often than reviews will. We could also have different TTLs for different types of queries. For instance, we could use 60 seconds for selecting a single review but only 5 seconds for selecting all reviews. Then we wouldn’t have to wait more than 5 seconds to see a new review appear on the reviews page.
SQL’s like syntax is followed by a search pattern that can include the % wildcard, which takes the place of zero or more characters.
Now let’s see if it works by running npm run dev and making queries in Playground:
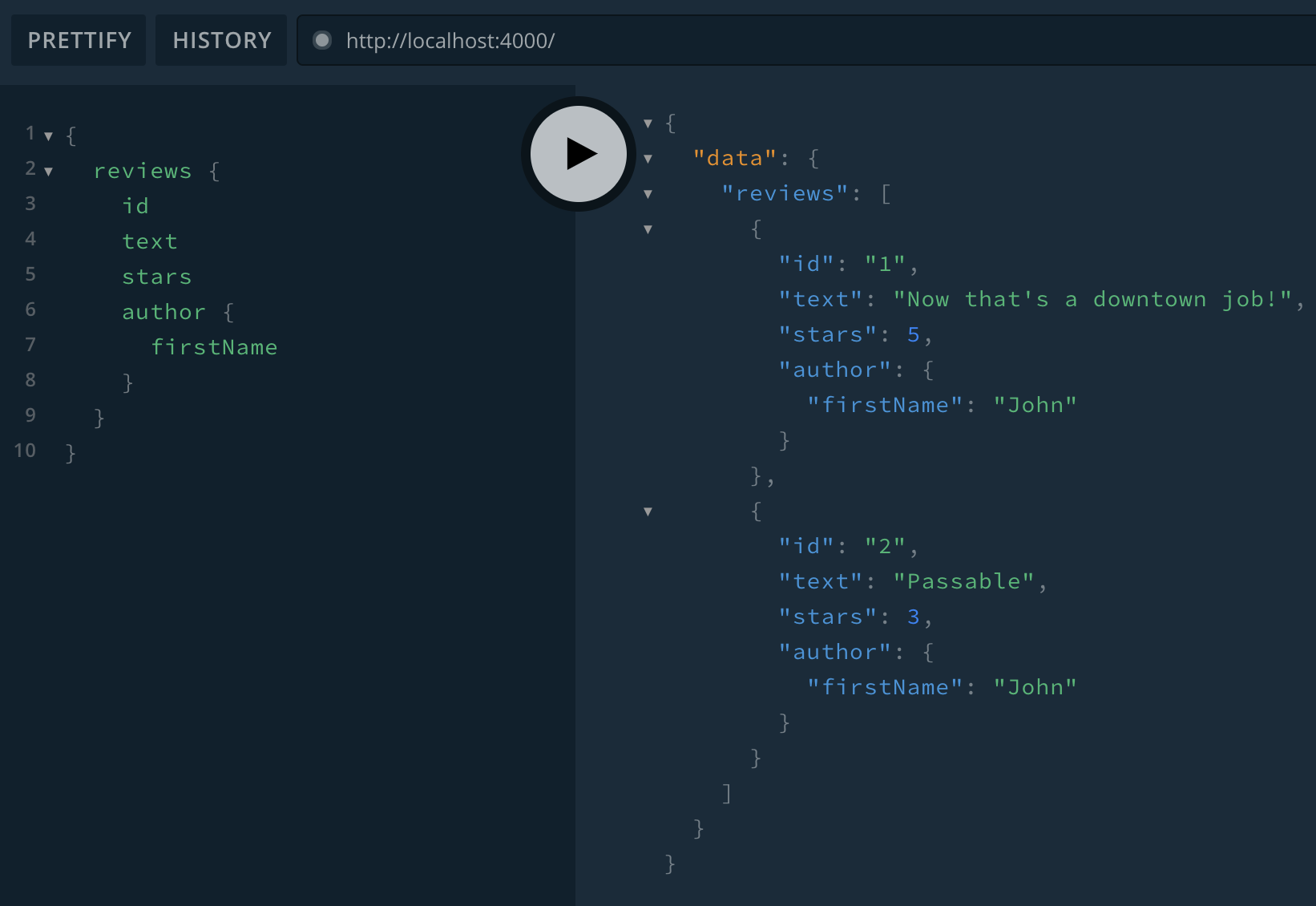
😃 Looks like it’s working! ...but not if we select a Date field:
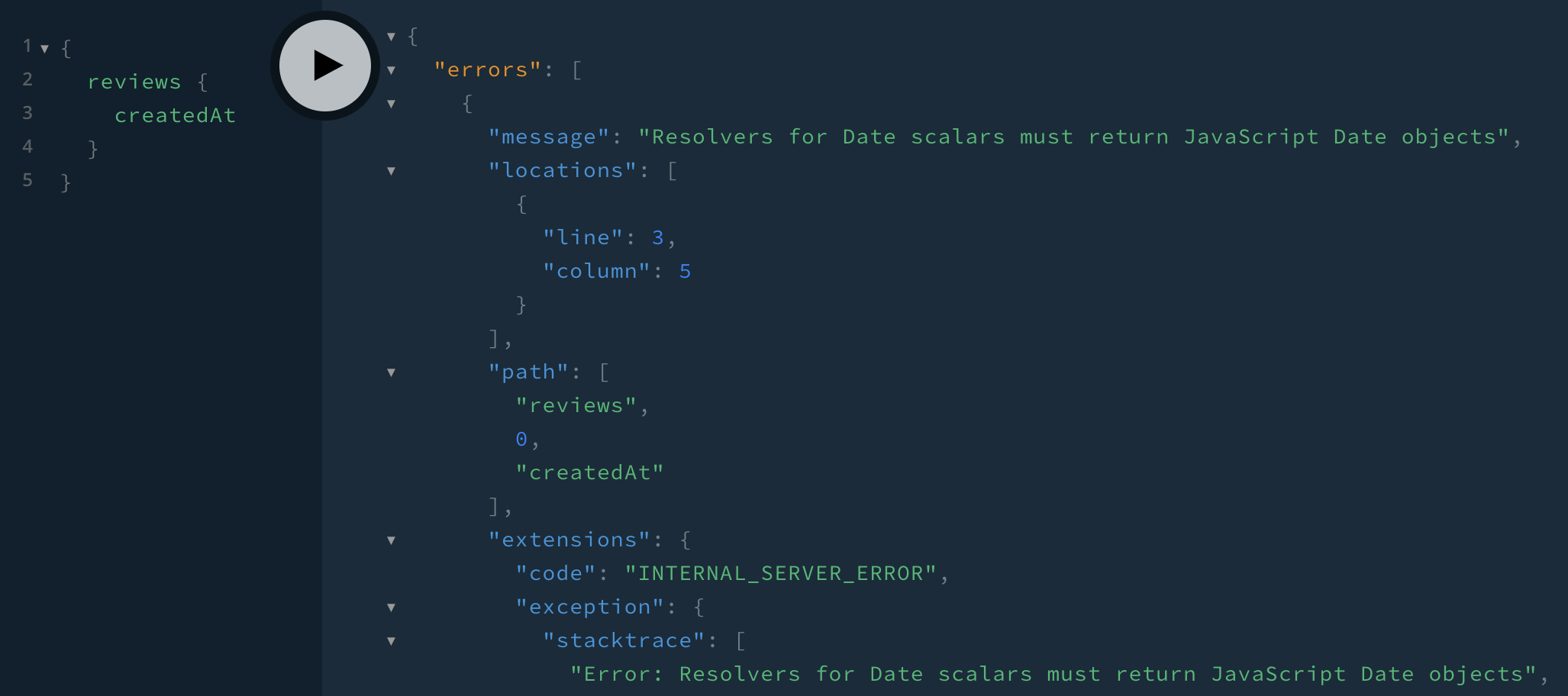
😞 The stacktrace points to this part of src/resolvers/Date.js:
serialize(date) {
if (!(date instanceof Date)) {
throw new Error(
'Resolvers for Date scalars must return JavaScript Date objects'
)
}
if (!isValid(date)) {
throw new Error('Invalid Date scalar')
}
return date.getTime()
}Remember when we wrote that? A custom scalar’s serialize() function is called when a value is returned from a resolver, and it formats the value for being sent to the client. When we were querying MongoDB, our results—for instance review.createdAt—were JavaScript Date objects, and we formatted them as integers. But when we query SQL datetime fields, we get them as integers, so we don’t need to format them differently for sending to the client. Similarly, when we receive values from the client, we don’t need to convert them to Date objects in parseValue() and parseLiteral(). However, we can still check to make sure they’re valid date integers:
import { GraphQLScalarType } from 'graphql'
import { Kind } from 'graphql/language'
const isValid = date => !isNaN(date.getTime())
export default {
Date: new GraphQLScalarType({
name: 'Date',
description:
'The `Date` scalar type represents a single moment in time. It is serialized as an integer, equal to the number of milliseconds since the Unix epoch.',
parseValue(value) {
if (!Number.isInteger(value)) {
throw new Error('Date values must be integers')
}
const date = new Date(value)
if (!isValid(date)) {
throw new Error('Invalid Date value')
}
return value
},
parseLiteral(ast) {
if (ast.kind !== Kind.INT) {
throw new Error('Date literals must be integers')
}
const dateInt = parseInt(ast.value)
const date = new Date(dateInt)
if (!isValid(date)) {
throw new Error('Invalid Date literal')
}
return dateInt
},
serialize(date) {
if (!Number.isInteger(date)) {
throw new Error('Resolvers for Date scalars must return integers')
}
if (!isValid(new Date(date))) {
throw new Error('Invalid Date scalar')
}
return date
}
})
}For parseValue(), the value is already an integer. For parseLiteral(), we get a string, so we use parseInt().
The last thing we need to update is our root query field isoString(date: Date):
isoString: (_, { date }) => date.toISOString()date used to be a Date instance, but now it’s an integer, so we can’t call toISOString() until we create a Date object. But strangely enough, we can’t create a Date object because the Date identifier is being used later in the file:
import Date from './Date'So we also need to change what we call the Date resolvers we’re importing:
const resolvers = {
Query: {
hello: () => '🌍🌏🌎',
isoString: (_, { date }) => new Date(date).toISOString()
}
}
import Review from './Review'
import User from './User'
import DateResolvers from './Date'
import Github from './Github'
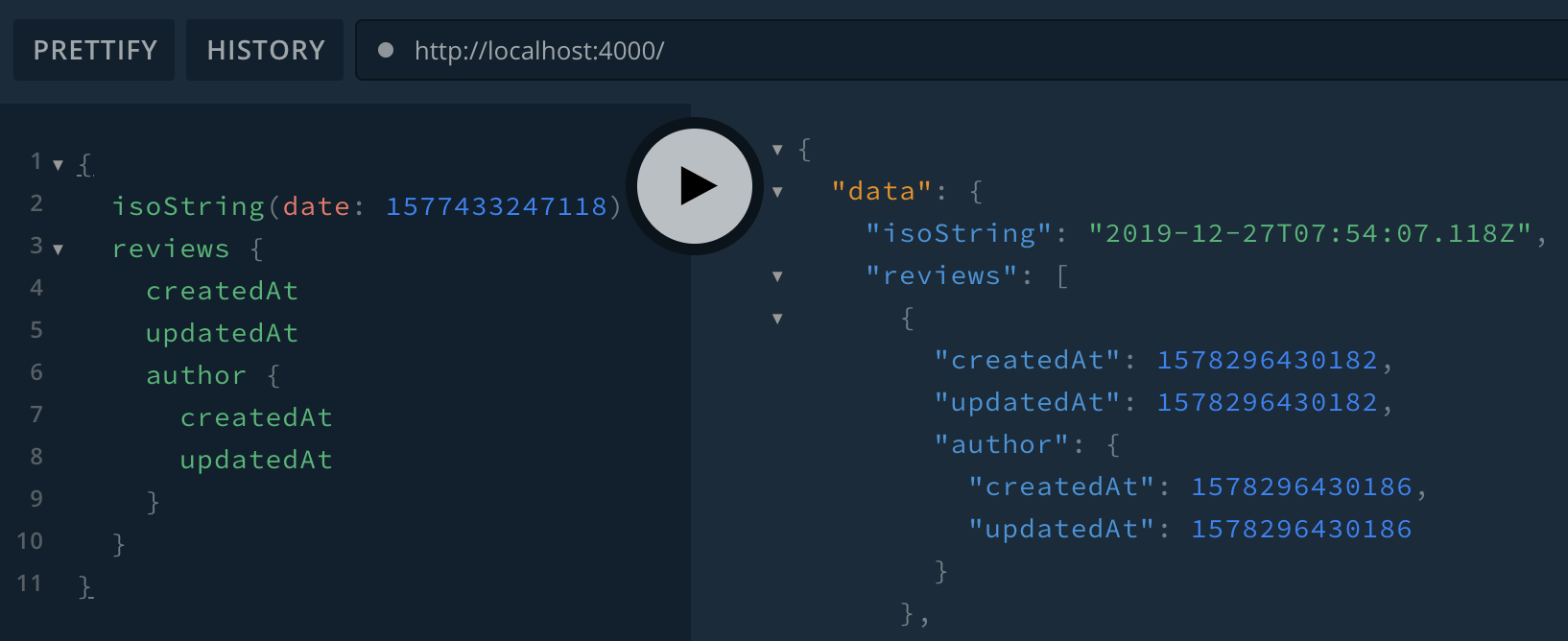
export default [resolvers, Review, User, DateResolvers, Github]Now all our dates are working:
SQL testing
If you’re jumping in here,
git checkout sql2_0.2.0(tag sql2_0.2.0, or compare sql2...sql3)
In the last section we implemented and used (okay, more like used then implemented 😄) our SQL data source. We also made a couple of queries to see if it worked, and the queries did work (eventually), but it wasn’t a comprehensive test. Let’s update our automated tests (which are currently broken) so we can have a higher level of confidence in our code’s correctness.
The place to start updating is in the code at the base of all our tests, test/guide-test-utils.js. We need to:
- Update mocked data field names (
_id -> idandfirstName -> first_name) and values. - Mock our new SQL data source.
- Remove our old data sources and database connection code.
import { ApolloServer } from 'apollo-server'
import { promisify } from 'util'
import { HttpLink } from 'apollo-link-http'
import fetch from 'node-fetch'
import { execute, toPromise } from 'apollo-link'
import {
server,
typeDefs,
resolvers,
context as defaultContext,
formatError
} from '../src/'
const created_at = new Date('2020-01-01').getTime()
const updated_at = created_at
export const mockUser = {
id: 1,
first_name: 'First',
last_name: 'Last',
username: 'mockA',
auth_id: 'mockA|1',
email: '[email protected]',
created_at,
updated_at
}
const mockUsers = [mockUser]
const reviewA = {
id: 1,
text: 'A+',
stars: 5,
created_at,
updated_at,
author_id: mockUser.id
}
const reviewB = {
id: 2,
text: 'Passable',
stars: 3,
created_at,
updated_at,
author_id: mockUser._id
}
const mockReviews = [reviewA, reviewB]
class SQL {
getReviews() {
return mockReviews
}
createReview() {
return reviewA
}
createUser() {
return mockUser
}
getUser() {
return mockUser
}
searchUsers() {
return mockUsers
}
}
export const db = new SQL()
export const createTestServer = ({ context = defaultContext } = {}) => {
const server = new ApolloServer({
typeDefs,
resolvers,
dataSources: () => ({ db }),
context,
formatError,
engine: false
})
return { server, dataSources: { db } }
}
export const startE2EServer = async () => {
const e2eServer = await server.listen({ port: 0 })
const stopServer = promisify(e2eServer.server.close.bind(e2eServer.server))
const link = new HttpLink({
uri: e2eServer.url,
fetch
})
return {
stop: stopServer,
request: operation => toPromise(execute(link, operation))
}
}
export { createTestClient } from 'apollo-server-testing'
export { default as gql } from 'graphql-tag'In our User resolver tests, we also need to update field names:
import {
createTestServer,
createTestClient,
gql,
mockUser
} from 'guide-test-utils'
const ME = gql`
query {
me {
id
}
}
`
test('me', async () => {
const { server } = createTestServer({
context: () => ({ user: { id: 'itme' } })
})
const { query } = createTestClient(server)
const result = await query({ query: ME })
expect(result.data.me.id).toEqual('itme')
})
const USER = gql`
query User($id: ID!) {
user(id: $id) {
id
}
}
`
test('user', async () => {
const { server } = createTestServer()
const { query } = createTestClient(server)
const id = mockUser.id
const result = await query({
query: USER,
variables: { id }
})
expect(result.data.user.id).toEqual(id.toString())
})
const CREATE_USER = gql`
mutation CreateUser($user: CreateUserInput!, $secretKey: String!) {
createUser(user: $user, secretKey: $secretKey) {
id
}
}
`
test('createUser', async () => {
const { server } = createTestServer()
const { mutate } = createTestClient(server)
const user = {
firstName: mockUser.first_name,
lastName: mockUser.last_name,
username: mockUser.username,
email: mockUser.email,
authId: mockUser.auth_id
}
const result = await mutate({
mutation: CREATE_USER,
variables: {
user,
secretKey: process.env.SECRET_KEY
}
})
expect(result).toMatchSnapshot()
})Now if we run npm test, we see tests fail due to mismatching snapshots, which we can update with npx jest -u.
One thing we updated in the last section that we don’t have a test for is the context function:
import { AuthenticationError } from 'apollo-server'
import { getAuthIdFromJWT } from './util/auth'
import { db } from './data-sources/'
export default async ({ req }) => {
const context = {}
const jwt = req && req.headers.authorization
let authId
if (jwt) {
try {
authId = await getAuthIdFromJWT(jwt)
} catch (e) {
let message
if (e.message.includes('jwt expired')) {
message = 'jwt expired'
} else {
message = 'malformed jwt in authorization header'
}
throw new AuthenticationError(message)
}
const user = await db.getUser({ auth_id: authId })
if (user) {
context.user = user
} else {
throw new AuthenticationError('no such user')
}
}
return context
}Let’s write a test for it! In order to test it, we have two options:
- Using an authorization header that successfully decodes to our mock
auth_id:mockA|1. We can’t create such a JWT, and, even if we could, it would expire. And then our test would fail. - Make it a unit test and mock all the functions it calls—in this case
getAuthIdFromJWT()anddb.getUser().
Let’s do the second. To mock an import, we need to call jest.mock(file):
import { mockUser } from 'guide-test-utils'
jest.mock('./util/auth', () => ({
getAuthIdFromJWT: jest.fn(jwt => (jwt === 'valid' ? mockUser.auth_id : null))
}))
jest.mock('./data-sources/', () => ({
db: {
getUser: ({ auth_id }) => (auth_id === mockUser.auth_id ? mockUser : null)
}
}))Now when any code we’re testing does the below imports, it will get our mock implementations.
import { getAuthIdFromJWT } from './util/auth'
import { db } from './data-sources/'Let’s test the success case first:
import getContext from './context'
import { getAuthIdFromJWT } from './util/auth'
describe('context', () => {
it('finds a user given a valid jwt', async () => {
const context = await getContext({
req: { headers: { authorization: 'valid' } }
})
expect(getAuthIdFromJWT.mock.calls.length).toBe(1)
expect(context.user).toMatchSnapshot()
})
})We can check our snapshot:
src/__snapshots__/context.test.js.snap
// Jest Snapshot v1, https://goo.gl/fbAQLP
exports[`context finds a user given a valid jwt 1`] = `
Object {
"auth_id": "mockA|1",
"created_at": 1577836800000,
"email": "[email protected]",
"first_name": "First",
"id": 1,
"last_name": "Last",
"updated_at": 1577836800000,
"username": "mockA",
}
`;✅ Looks good! Next let’s make sure that giving an invalid JWT throws an error:
import { AuthenticationError } from 'apollo-server’
describe('context', () => {
it('finds a user given a valid jwt', async () => { ... }
it('throws error on invalid jwt', async () => {
const promise = getContext({
req: { headers: { authorization: 'invalid' } }
})
expect(getAuthIdFromJWT.mock.calls.length).toBe(1)
expect(promise).rejects.toThrow(AuthenticationError)
})
})We see with npx jest context that the test fails, saying that the getAuthIdFromJWT mock was called twice.
Adding
contextafternpx jestlimits testing to files with “context” in their names.
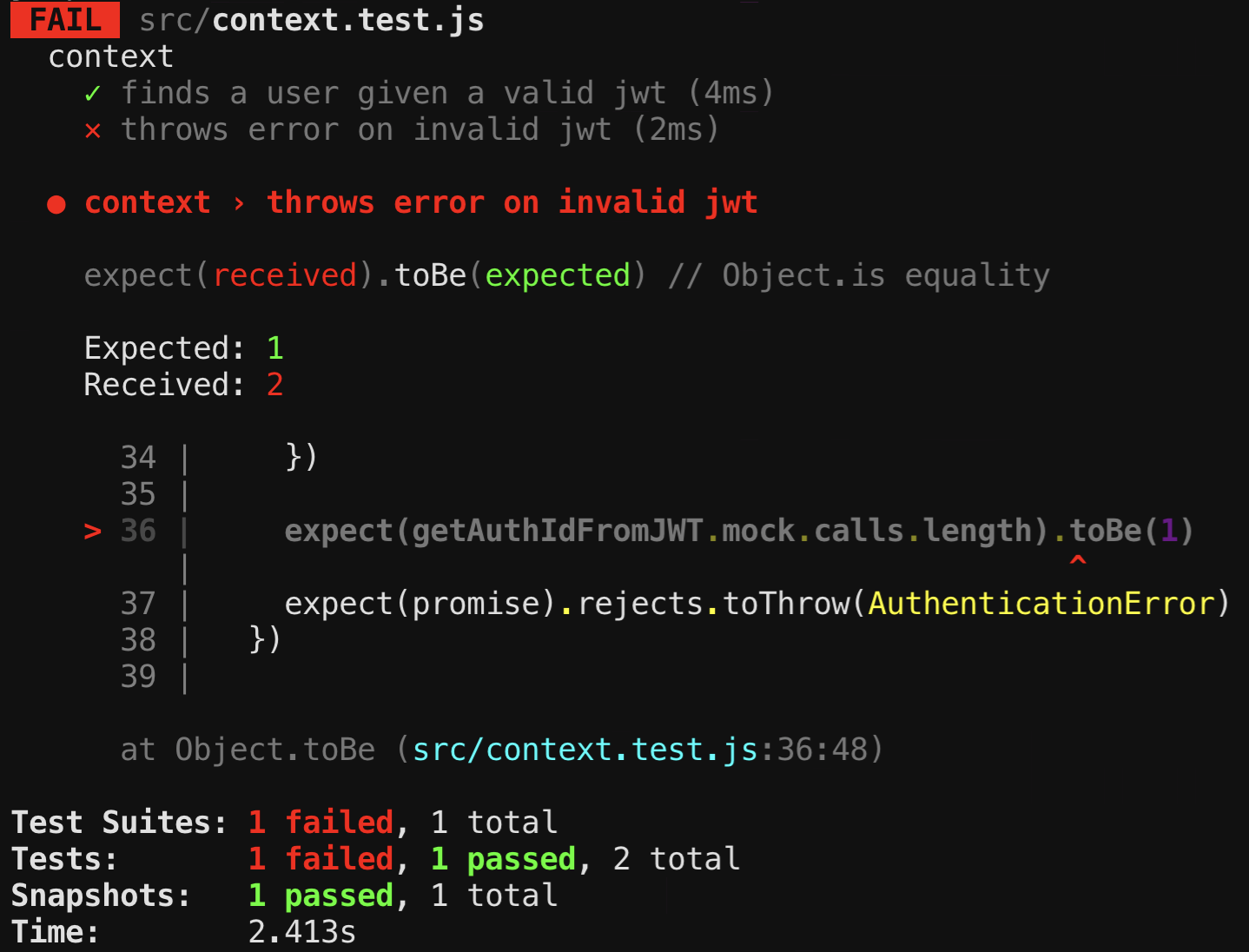
The mock calls are cumulative until we clear the mock. Let’s do that after each test:
describe('context', () => {
afterEach(() => {
getAuthIdFromJWT.mockClear()
})
it('finds a user given a valid jwt', async () => { ... }
it('throws error on invalid jwt', async () => {
const promise = getContext({
req: { headers: { authorization: 'invalid' } }
})
expect(getAuthIdFromJWT.mock.calls.length).toBe(1)
expect(promise).rejects.toThrow(AuthenticationError)
})
})✅ And we’re back to green. Lastly, let’s test a blank auth header:
describe('context', () => {
afterEach(() => {
getAuthIdFromJWT.mockClear()
})
it('finds a user given a valid jwt', async () => { ... }
it('throws error on invalid jwt', async () => { ... }
it('is empty without jwt', async () => {
const context = await getContext({
req: { headers: {} }
})
expect(getAuthIdFromJWT.mock.calls.length).toBe(0)
expect(context).toEqual({})
})
})✅ And still green! 💃 All together, that’s:
import { AuthenticationError } from 'apollo-server'
import { mockUser } from 'guide-test-utils'
import getContext from './context'
import { getAuthIdFromJWT } from './util/auth'
jest.mock('./util/auth', () => ({
getAuthIdFromJWT: jest.fn(jwt => (jwt === 'valid' ? mockUser.auth_id : null))
}))
jest.mock('./data-sources/', () => ({
db: {
getUser: ({ auth_id }) => (auth_id === mockUser.auth_id ? mockUser : null)
}
}))
describe('context', () => {
afterEach(() => {
getAuthIdFromJWT.mockClear()
})
it('finds a user given a valid jwt', async () => {
const context = await getContext({
req: { headers: { authorization: 'valid' } }
})
expect(getAuthIdFromJWT.mock.calls.length).toBe(1)
expect(context.user).toMatchSnapshot()
})
it('throws error on invalid jwt', async () => {
const promise = getContext({
req: { headers: { authorization: 'invalid' } }
})
expect(getAuthIdFromJWT.mock.calls.length).toBe(1)
expect(promise).rejects.toThrow(AuthenticationError)
})
it('is empty without jwt', async () => {
const context = await getContext({
req: { headers: {} }
})
expect(getAuthIdFromJWT.mock.calls.length).toBe(0)
expect(context).toEqual({})
})
})Unfortunately if we run npm test, we see our coverage is down to 40%. And if we look at the coverage report (npm run open-coverage), we see not much of our SQL data source is covered:
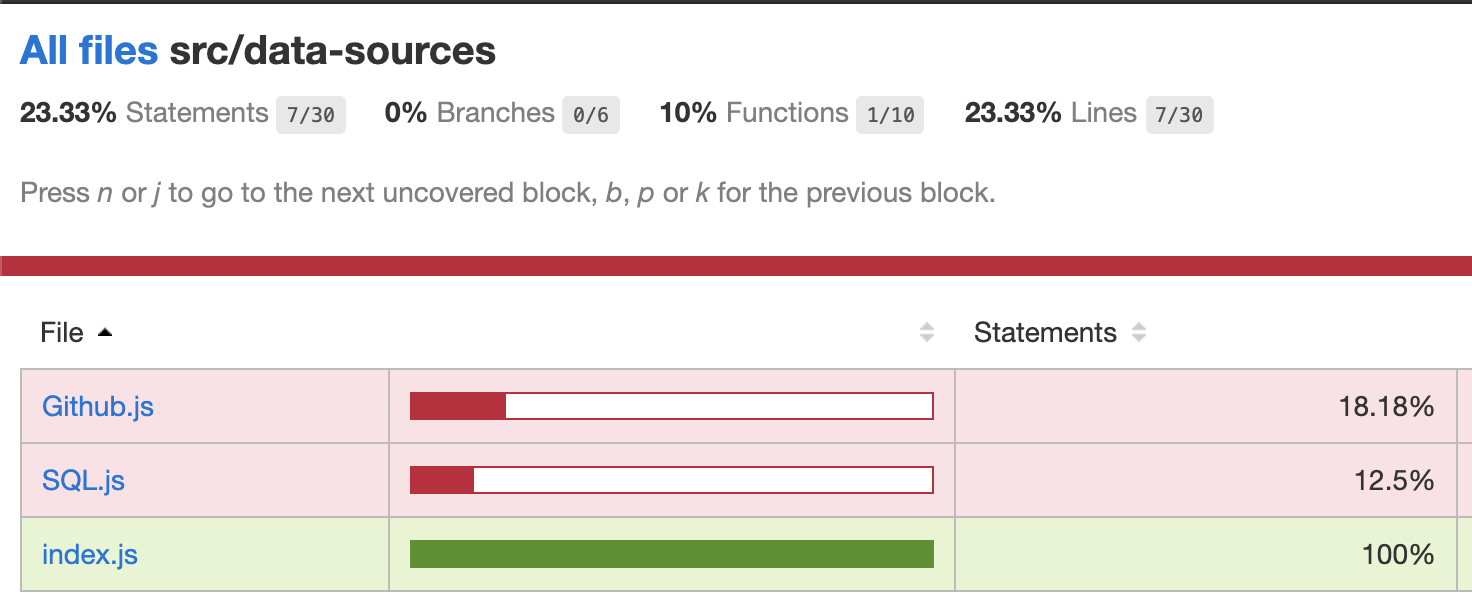
Our old Users.js and Reviews.js files were 100% covered:
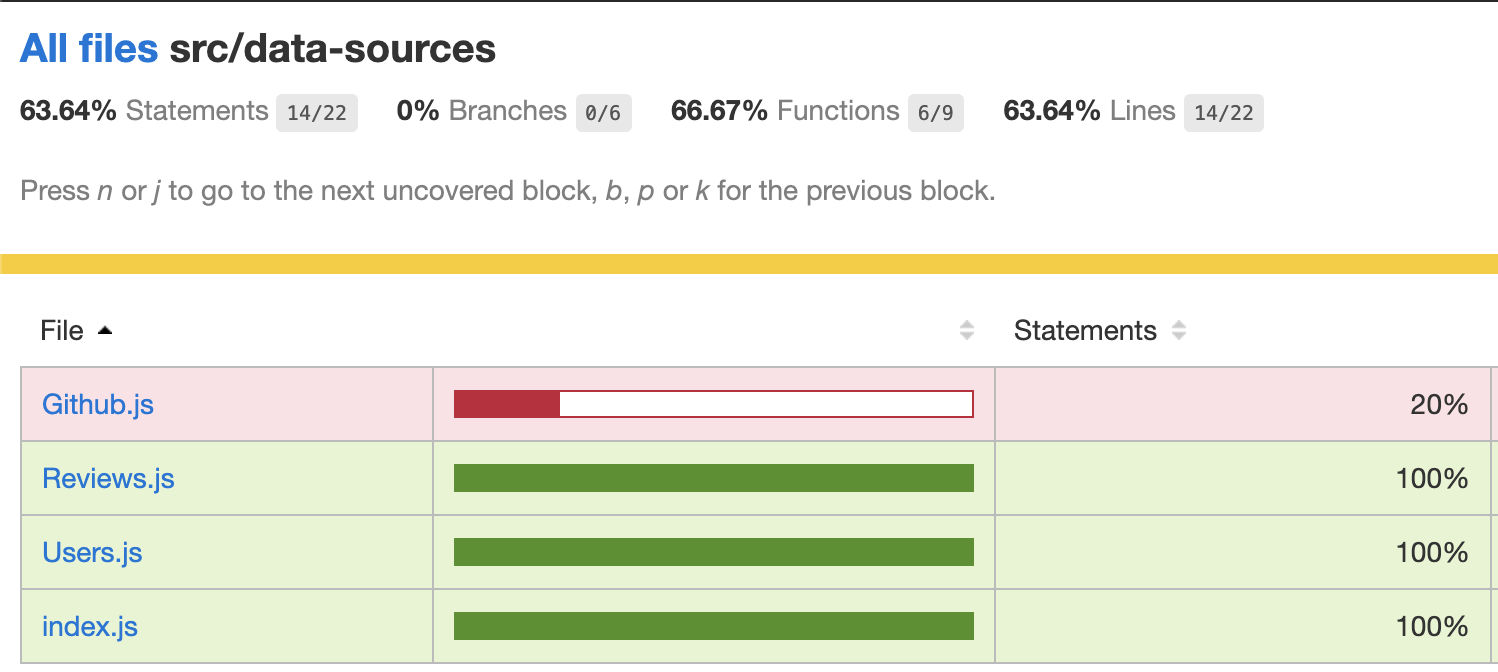
The issue is that before, we were mocking the .find() and .insertOne() methods of MongoDB collections, and currently, we’re mocking the data source methods:
class SQL {
getReviews() {
return mockReviews
}
createReview() {
return reviewA
}
createUser() {
return mockUser
}
getUser() {
return mockUser
}
searchUsers() {
return mockUsers
}
}If we wanted to cover SQL.js, we would need to run the actual methods, which means we would need to instead mock the this.knex used by the methods.
SQL performance
If you’re jumping in here,
git checkout sql3_0.2.0(tag sql3_0.2.0, or compare sql3...sql4)
The two main performance factors when it comes to database querying are latency and load. Latency is how quickly we get all the data we need, and load is how much work the database is doing. Latency usually won’t be an issue unless we have complex queries or a lot of data. Load won’t be an issue unless we have a lot of clients simultaneously using our API.
When neither latency nor load is an issue for our app, we don’t need to concern ourselves with performance, and our current implementation is fine. If either becomes an issue (or if we’re certain that it will be when our API is completed and released), then we have different ways we can improve performance. This section is mainly about using SQL JOIN statements, which we’re currently not using. We discuss more performance topics in the Performance section later in the chapter.
Let’s consider this GraphQL query:
{
reviews {
id
text
author {
firstName
}
}
}If we were writing an efficient SQL statement to fetch that data, we’d write:
SELECT reviews.id, reviews.text, users.first_name
FROM reviews
LEFT JOIN users
ON reviews.author_id = users.idLet’s compare this statement to what happens with our current server. We can have Knex print out statements it sends by adding a DEBUG=knex:query env var. When we do that and make the above GraphQL query, we see these three SQL statements:
$ DEBUG=knex:query npm run dev
GraphQL server running at http://localhost:4000/
SQL (1.437 ms) select * from `reviews`
SQL (0.364 ms) select * from `users` where `id` = 1
SQL (0.377 ms) select * from `users` where `id` = 1There are a few issues with this:
- There are 3 queries instead of 1. (And more generally, there are
N+1queries, whereNis the number of reviews.) - They all select
*instead of just the fields needed. - The second two are redundant (they occur because SQLDataSource doesn’t do batching).
This probably will result in a higher load on the SQL server than the single efficient statement we wrote. It also has a higher latency, since not all of the three statements are sent at the same time—first the reviews are fetched, then the author_ids are used to create the rest of the statements. That’s two round trips over the network from the API server to the database instead of the one trip our efficient statement took.
Let’s change our code to use a JOIN like the efficient statement did. Currently, the reviews root Query field calls the getReviews() data source method:
class SQL extends SQLDataSource {
getReviews() {
return this.knex
.select('*')
.from('reviews')
.cache(REVIEW_TTL)
}
...
}We can add a .leftJoin():
import { pick } from 'lodash'
class SQL extends SQLDataSource {
async getReviews() {
const reviews = await this.knex
.select(
'users.*',
'users.created_at as users__created_at',
'users.updated_at as users__updated_at',
'reviews.*'
)
.from('reviews')
.leftJoin('users', 'users.id', 'reviews.author_id')
.cache(REVIEW_TTL)
return reviews.map(review => ({
...review,
author: {
id: review.author_id,
created_at: review.users__created_at,
updated_at: review.users__updated_at,
...pick(review, 'first_name', 'last_name', 'email', 'photo')
}
}))
}
...
}We needed to change our .select('*') because both users and reviews have created_at and updated_at columns. We also needed to use .map() to extract out the user fields into an author object.
Finally, we need to stop the Review.author resolver from querying the database. We can do so by checking if the author object is already present on the review object:
export default {
Query: ...
Review: {
author: (review, _, { dataSources: { db } }) =>
review.author || db.getUser({ id: review.author_id }),
...
}Now when we run the same GraphQL query in Playground, we see this SQL statement is executed:
SQL (1.873 ms) select `reviews`.*, `users`.`created_at` as `users__created_at`, `users`.`updated_at` as `users__updated_at` from `reviews` left join `users` on `users`.`id` = `reviews`.`author_id`Success! We went from three statements down to one. However, there are still inefficiencies. The SQL statement is overfetching in two ways:
- It’s selecting all fields, whereas the GraphQL query only needed
id,text, andauthor.firstName. - It always does a JOIN, even when the GraphQL query doesn’t select
Review.author.
We can write code to address both these things—by looking through the fourth argument to resolvers, info, which contains information about the current GraphQL query, and seeing which fields are selected. However, it would be easier to use the Join Monster library, which does this for us.
To set it up, we create a new file to add the following information to our schema:
import joinMonsterAdapt from 'join-monster-graphql-tools-adapter'
export default schema =>
joinMonsterAdapt(schema, {
Query: {
fields: {
user: {
where: (users, args) => `${users}.id = ${args.id}`
}
}
},
Review: {
sqlTable: 'reviews',
uniqueKey: 'id',
fields: {
author: {
sqlJoin: (reviews, users) =>
`${reviews}.author_id = ${users}.id`
},
text: { sqlColumn: 'text' },
stars: { sqlColumn: 'stars' },
fullReview: { sqlDeps: ['text', 'stars', 'author_id'] },
createdAt: { sqlColumn: 'created_at' },
updatedAt: { sqlColumn: 'updated_at' }
}
},
User: {
sqlTable: 'users',
uniqueKey: 'id',
fields: {
firstName: { sqlColumn: 'first_name' },
lastName: { sqlColumn: 'last_name' },
createdAt: { sqlColumn: 'created_at' },
updatedAt: { sqlColumn: 'updated_at' },
photo: { sqlDeps: ['auth_id'] }
}
}
})We’re using the
join-monster-graphql-tools-adapterpackage, which we need when defining our schema in SDL format viagraphql-toolsor Apollo Server. (We wouldn’t need an adapter if we defined our schema in code withgraphql-js.)
We tell Join Monster:
- Which table each type corresponds to.
- Which column each field corresponds to.
- Query information for fields that involve SQL statements. For example,
Query.user’s WHERE clause matches theidargument with theidfield in the users table, andReview.authorcan be fetched with a JOIN on the users table. - When we need it to fetch fields that aren’t in the GraphQL query. For example, if
User.firstNameis in the query, it knows to fetch and returnfirst_name:
firstName: { sqlColumn: 'first_name' },But for User.photo, there’s no photo column in the users table. So our User.photo resolver will run, but it needs access to the user’s auth_id field. We need to tell Join Monster when User.photo is in the query, it needs to fetch auth_id from the database:
photo: { sqlDeps: ['auth_id'] }We call our configuration function with a schema created by makeExecutableSchema, and then we pass the schema to ApolloServer() (whereas before we were passing typeDefs and resolvers):
import { makeExecutableSchema } from 'graphql-tools'
import joinMonsterAdapter from './joinMonsterAdapter'
export const schema = makeExecutableSchema({
typeDefs,
resolvers
})
joinMonsterAdapter(schema)
const server = new ApolloServer({
schema,
dataSources,
context,
formatError
})
...We’re also going to need a Knex instance, which we’ll add here:
import Knex from 'knex'
const knexConfig = {
client: 'sqlite3',
connection: {
filename: './sql/dev.sqlite3'
},
useNullAsDefault: true
}
export const knex = Knex(knexConfig)And lastly, we update our Query.user and Query.review resolvers:
import joinMonster from 'join-monster'
import { knex } from '../data-sources/'
export default {
Query: {
me: ...
user: (_, __, context, info) =>
joinMonster(info, context, sql => knex.raw(sql), {
dialect: 'sqlite3'
}),
...
}
...
}import joinMonster from 'join-monster'
import { knex } from '../data-sources/'
export default {
Query: {
reviews: (_, __, context, info) =>
joinMonster(info, context, sql => knex.raw(sql), {
dialect: 'sqlite3'
})
},
...
}That was certainly simpler than the long getReviews() method we wrote! Instead, we give joinMonster() the info and context, and it gives us a SQL statement to run.
We also get to remove some resolvers that will be taken care of by Join Monster:
User.firstName
User.lastName
User.createdAt
User.updatedAt
Review.author
Review.createdAt
Review.updatedAtNow when we query for a user and select firstName, createdAt, and photo:
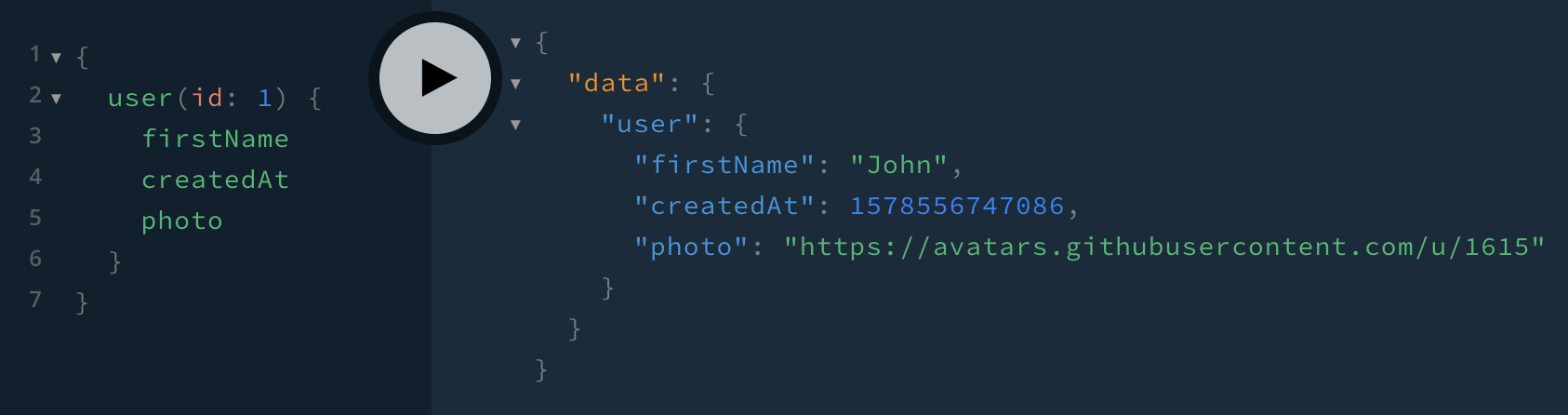
this SELECT statement gets run:
GraphQL server running at http://localhost:4000/
knex:query SELECT
knex:query "user"."id" AS "id",
knex:query "user"."first_name" AS "firstName",
knex:query "user"."created_at" AS "createdAt",
knex:query "user"."auth_id" AS "auth_id"
knex:query FROM users "user"
knex:query WHERE "user".id = 1 +16sJoin Monster knows to get 1 from the query argument to use in the WHERE clause, it knows to look in the users table, and it knows exactly which fields to fetch, even auth_id.
Here’s another example of sqlDeps working. From the config:
fullReview: { sqlDeps: ['text', 'stars', 'author_id'] },When we send this query:
{
reviews {
fullReview
}
}all three deps are selected:
knex:query SELECT
knex:query "reviews"."id" AS "id",
knex:query "reviews"."text" AS "text",
knex:query "reviews"."stars" AS "stars",
knex:query "reviews"."author_id" AS "author_id"
knex:query FROM reviews "reviews" +0ms
SQL (0.980 ms) select * from `users` where `id` = 1
SQL (0.367 ms) select * from `users` where `id` = 1Join Monster doesn’t yet support a joined object type as a field dependency, which is why we list author_id instead of author in sqlDeps, and why the Review.fullReview resolver still has to call db.getUser().
Lastly, let’s see how it handles a reviews query with author selected:
{
reviews {
author {
lastName
}
}
} knex:query SELECT
knex:query "reviews"."id" AS "id",
knex:query "author"."id" AS "author__id",
knex:query "author"."last_name" AS "author__lastName"
knex:query FROM reviews "reviews"
knex:query LEFT JOIN users "author" ON "reviews".author_id = "author".id +3m✨ Perfect! It only fetched the fields needed and used a single statement.