Pagination
Implementing 3 different forms of GraphQL pagination
To view this content, buy the book! 😃🙏
Or if you’ve already purchased.
Pagination
Pagination is the general term for requesting chunks of a list of data instead of the whole list, because requesting the whole list would take too much time or resources. In Chapter 6: Paginating, we covered different types of pagination from the client’s perspective. In this section, we’ll cover them from the server’s perspective: Defining the schema and writing code that fetches the requested chunk of data from the database.
These are the main types of pagination:
- Offset-based: Request a chunk at an offset from the beginning of the list.
- Pages: Request Nth page of a certain size. For instance,
page: 3, size: 10would be items 21-30. - Skip & limit: Request limit items after skipping skip items. For instance
skip: 40, limit: 20would be items 41-60.
- Pages: Request Nth page of a certain size. For instance,
- Cursor-based: Request a chunk before or after a cursor. Conceptually, a cursor is a pointer to a location in a query’s result set. There’s a range of ways to implement it, both in terms of what arguments are used and how the schema looks. Here are a couple options:
- after an ID: Request limit items after some sortable field, like
id—in MongoDB, ObjectIds sort by the time they were created, like acreatedAttimestamp. This is the simplified, cursor-like system used in Chapter 6: Cursors. For instanceafter: '5d3202c4a044280cac1e2f60', limit: 10would be the 10 items after thatid. - Relay cursor connections: Request the first N items after an opaque cursor (or last N items before a cursor). For instance,
first: 10, after: 'abcabcabc', where'abcabcabc'contains an encoded result set location.
- after an ID: Request limit items after some sortable field, like
In Chapter 6, we used
[id]:[sort order]as the cursor format (like'100:createdAt_DESC'). However, it’s best practice for the client to treat cursors as opaque strings, and that’s usually facilitated by the server Base64-encoding the string. So the server would return'MTAwOmNyZWF0ZWRBdF9ERVND'as the cursor instead of'100:createdAt_DESC'.
The downsides to offset-based are:
- When the result set changes (items added or removed), we might miss or get duplicate results. (We discuss this scenario in Chapter 6: skip & limit.)
- The performance of a
LIMIT x OFFSET yquery does not scale well for large data sets in many databases, including PostgreSQL, MySQL, and MongoDB. (Note that depending on the flexibility of our collection structure, we might be able to use the bucket pattern in MongoDB to scale this query well.)
The downsides to cursor-based are:
- We can’t jump ahead, for example, from page 1 to page 5.
- The implementation is a little more complex.
In Offset-based, we’ll implement skip & limit. Then in Cursor-based, we’ll implement after an ID and Relay cursor connections.
Offset-based
If you’re jumping in here,
git checkout 25_0.2.0(tag 25_0.2.0, or compare 25...pagination)
In skip & limit, we have three arguments: skip, limit, and orderBy. Let’s update the schema first, then the resolver, and lastly the data sources.
For orderBy, we need a new enum type. The skip and limit arguments are integers. We can set default values for each so that we can make each argument nullable.
Here’s the current reviews Query:
extend type Query {
reviews: [Review!]!
}Here we add the arguments:
enum ReviewOrderBy {
createdAt_ASC
createdAt_DESC
}
extend type Query {
reviews(skip: Int, limit: Int, orderBy: ReviewOrderBy): [Review!]!
}The convention for enum values is ALL_CAPS, but createdAt_ASC makes it more clear than CREATED_AT_ASC that it’s sorting by the Review.createdAt field. The subsequent underscore and all-caps ASC/DESC still demonstrate they’re enum values.
Learn the rules so you know how to break them properly. —The Dalai Lama’s Fifth Rule of Living
Our resolver is currently very simple:
export default {
Query: {
reviews: (_, __, { dataSources }) => dataSources.reviews.all()
},
...
}We need to add the arguments and check them. GraphQL execution adequately checks orderBy (so we know it will either be the string 'createdAt_DESC' or 'createdAt_ASC'), but it only checks that skip and limit are integers. We also need to make sure they’re not invalid or restricted values. It doesn’t make sense for skip to be less than 0, nor for limit to be less than 1. We’ll also prevent large values of limit to protect against denial of service attacks.
const MAX_PAGE_SIZE = 100
export default {
Query: {
reviews: (
_,
{ skip = 0, limit = 10, orderBy = 'createdAt_DESC' },
{ dataSources }
) => {
const errors = {}
if (skip < 0) {
errors.skip = `must be non-negative`
}
if (limit < 1) {
errors.limit = `must be positive`
}
if (limit > MAX_PAGE_SIZE) {
errors.limit = `cannot be greater than ${MAX_PAGE_SIZE}`
}
if (!isEmpty(errors)) {
throw new InputError({ review: errors })
}
return dataSources.reviews.getPage({ skip, limit, orderBy })
}
},
...
}Lastly, call a new data source method getPage, which we’ll define next. Here’s our old .all() method:
export default class Reviews extends MongoDataSource {
all() {
return this.collection.find().toArray()
}
...
}We replace it with:
export default class Reviews extends MongoDataSource {
getPage({ skip, limit, orderBy }) {
return this.collection
.find()
.sort({ _id: orderBy === 'createdAt_DESC' ? -1 : 1 })
.skip(skip)
.limit(limit)
.toArray()
}
...
}
_idis an ObjectId, so sorting by_idis equivalent to sorting by acreatedAttimestamp.
Let’s first test the error case in Playground:
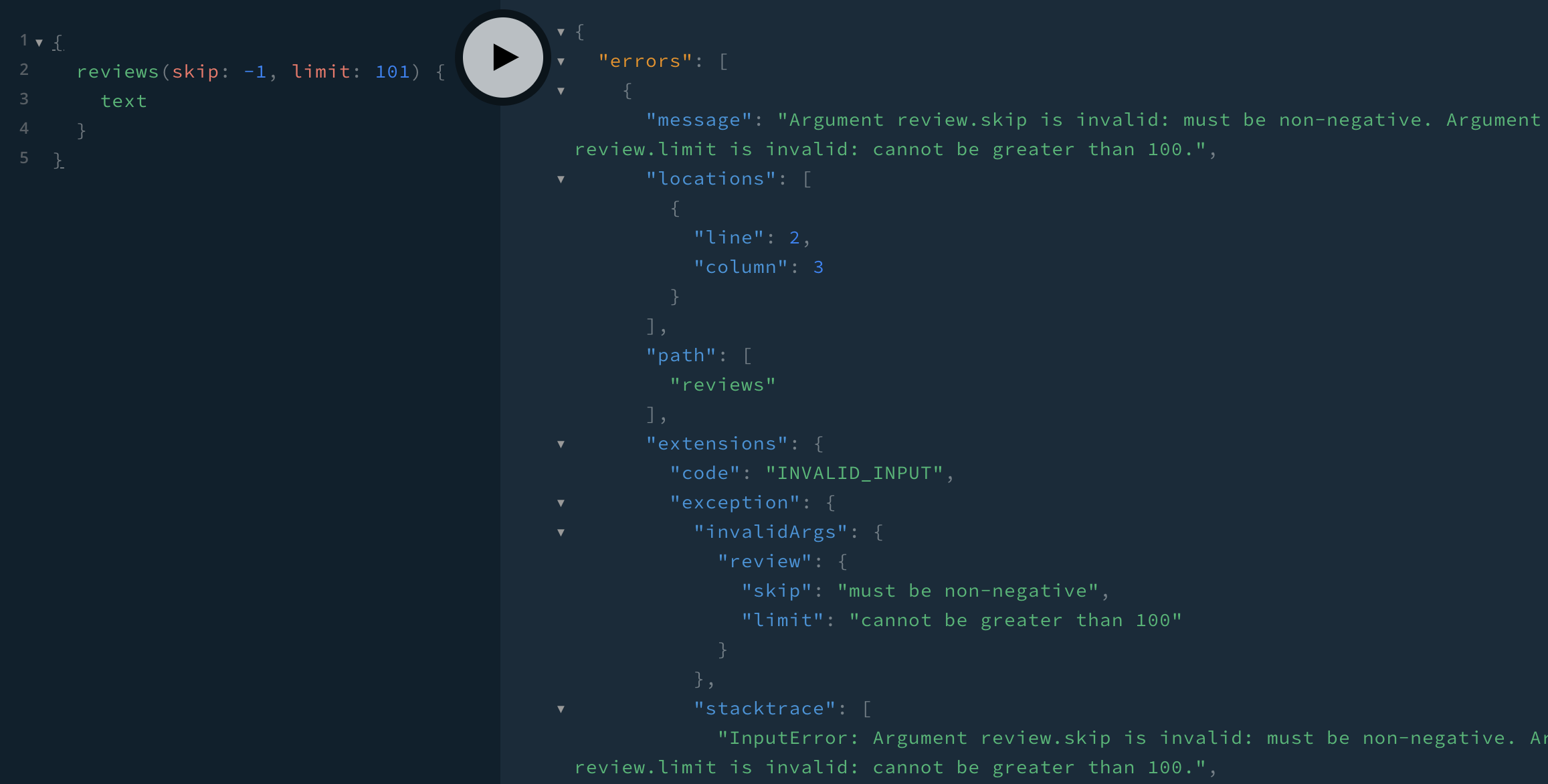
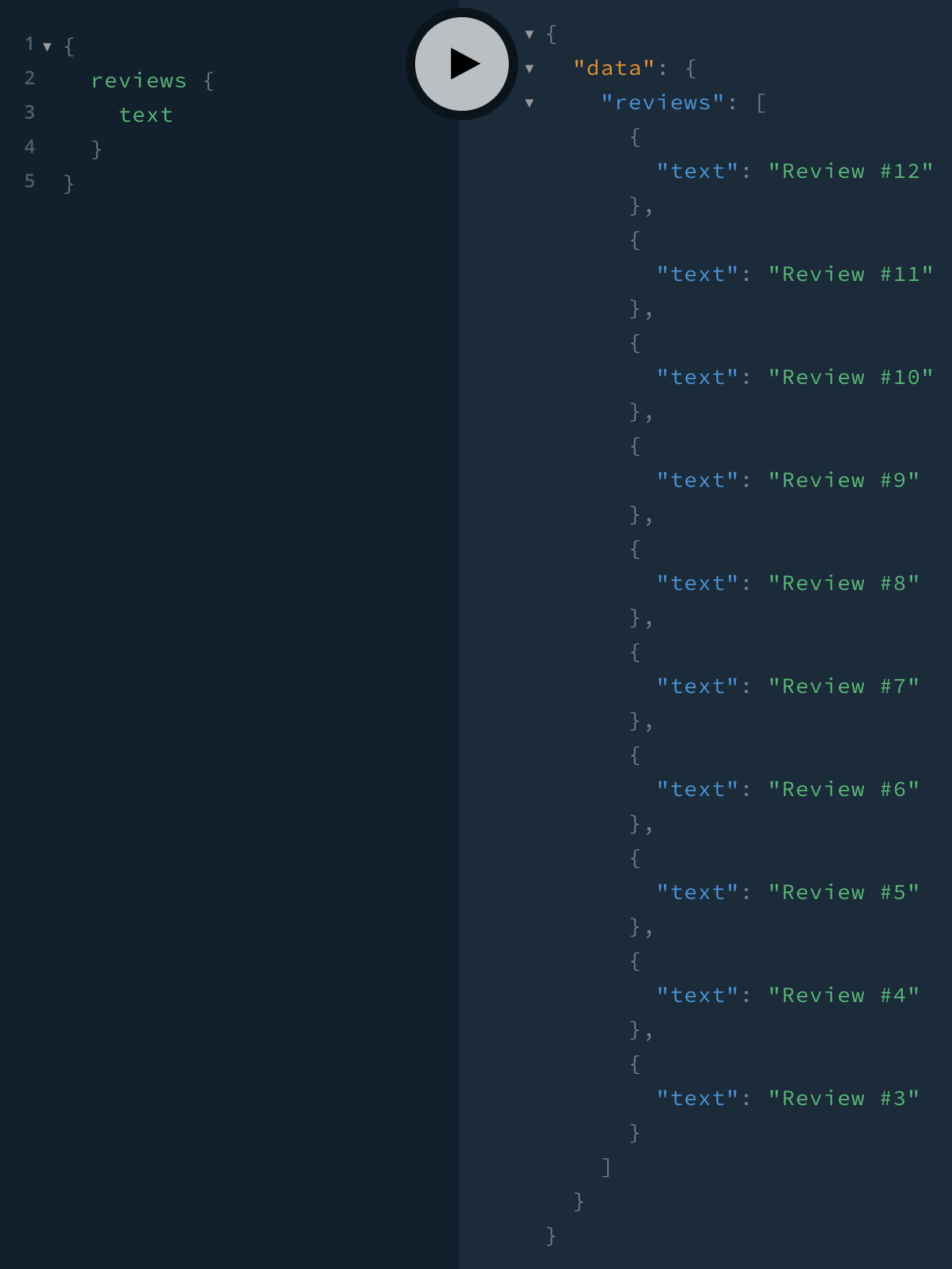
And with default arguments, we see the most recent 10 reviews:
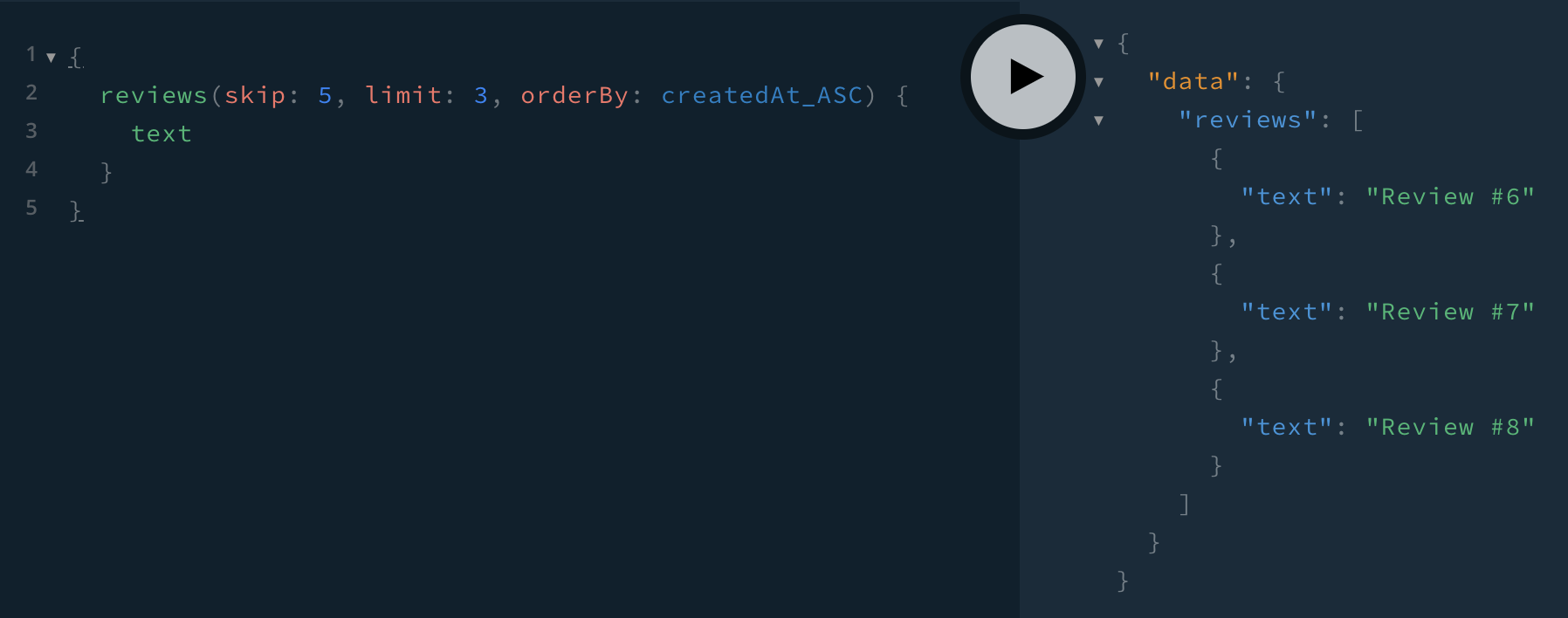
And with skip: 5, limit: 3, orderBy: createdAt_ASC, we see the 6th through 8th reviews:
Cursors
There are a number of ways to do cursor-based pagination:
afteran ID: Use three arguments to support cursor-like pagination for queries sorted by a single field (createdAt).first/after & last/before:firstandlastare equivalent tolimit, andafter/beforeis the cursor. These are added as arguments, but the client has to get the cursor from the server, which requires adding acursorfield to the schema. We can do this a few ways:- Add
cursorto each object. - Have each paginated query return a
startCursor, anendCursor, andnodes. - Use Relay cursor connections, where the paginated query returns edges, which each contain a
cursorand anode.
- Add
In this section, we will implement after an ID and Relay cursor connections.
#1 would have Review.cursor:
type Review {
id: ID!
author: User!
text: String!
stars: Int
fullReview: String!
createdAt: Date!
updatedAt: Date!
cursor: String
}
enum ReviewOrderBy {
createdAt_ASC
createdAt_DESC
}
extend type Query {
reviews(first: Int, after: String): [Review!]!
get(id: ID!): Review
}One downside to this approach is the cursor isn’t really part of a Review’s data. For instance, it’s not applicable when we do a get Query to fetch a single Review by ID.
#2 would fix that issue, since the cursor is no longer a Review field:
type ReviewsResult {
nodes: [Review!]!
startCursor: String!
endCursor: String!
}
extend type Query {
reviews(first: Int, after: String, last: Int, before: String): ReviewsResult!
get(id: ID!): Review
}We could also add information about the data set—the total number of items and whether there are more items available to query:
type ReviewsResult {
nodes: [Review!]!
startCursor: String!
endCursor: String!
totalCount: Int!
hasNextPage: Boolean!
hasPreviousPage: Boolean!
}#3 has the most involved schema, which we’ll go over in the last section:
type ReviewEdge {
cursor: String!
node: Review
}
type PageInfo {
startCursor: String!
endCursor: String!
hasNextPage: Boolean!
hasPreviousPage: Boolean!
}
type ReviewsConnection {
edges: [ReviewEdge]
pageInfo: PageInfo!
totalCount: Int!
}
extend type Query {
reviews(first: Int, after: String, last: Int, before: String): ReviewsConnection!
get(id: ID!): Review
}The main two benefits to #3 over #2 are:
- We have the cursor of every object—not just the start and end cursors—so we can request the next page starting at any location in the list.
- We can add more information to the edge. For instance if we had a social platform with a paginated
User.friendsfield returning aFriendsConnectionwithedges: [FriendEdge], aFriendEdgecould include:
type FriendEdge {
cursor: String!
node: Friend
becameFriendsOn: Date
mutualFriends: [Friends]
photosInCommon: [Photo]
}after an ID
If you’re jumping in here,
git checkout pagination_0.2.0(tag pagination_0.2.0, or compare pagination...pagination2)
In this section we’ll do a limited cursor-like pagination with these three arguments:
extend type Query {
reviews(after: ID, limit: Int, orderBy: ReviewOrderBy): [Review!]!
}The only change from skip & limit is instead of skiping a number of results, we return those after an ID. In our resolver, we change skip -> after and remove skip’s error checking:
export default {
Query: {
reviews: (
_,
{ after, limit = 10, orderBy = 'createdAt_DESC' },
{ dataSources }
) => {
const errors = {}
if (limit < 0) {
errors.limit = `must be non-negative`
}
if (limit > MAX_PAGE_SIZE) {
errors.limit = `cannot be greater than ${MAX_PAGE_SIZE}`
}
if (!isEmpty(errors)) {
throw new InputError({ review: errors })
}
return dataSources.reviews.getPage({ after, limit, orderBy })
}
},
...
}We could also check whether
afteris a validObjectId(as we do in theQuery.userresolver).
In the data source, if after is provided (it’s optional), we filter using either $lt or $gt (less than / greater than):
import { ObjectId } from 'mongodb'
export default class Reviews extends MongoDataSource {
getPage({ after, limit, orderBy }) {
const filter = {}
if (after) {
const afterId = ObjectId(after)
filter._id =
orderBy === 'createdAt_DESC' ? { $lt: afterId } : { $gt: afterId }
}
return this.collection
.find(filter)
.sort({ _id: orderBy === 'createdAt_DESC' ? -1 : 1 })
.limit(limit)
.toArray()
}
...
}To test, first let’s get the first 5 reviews with their IDs:
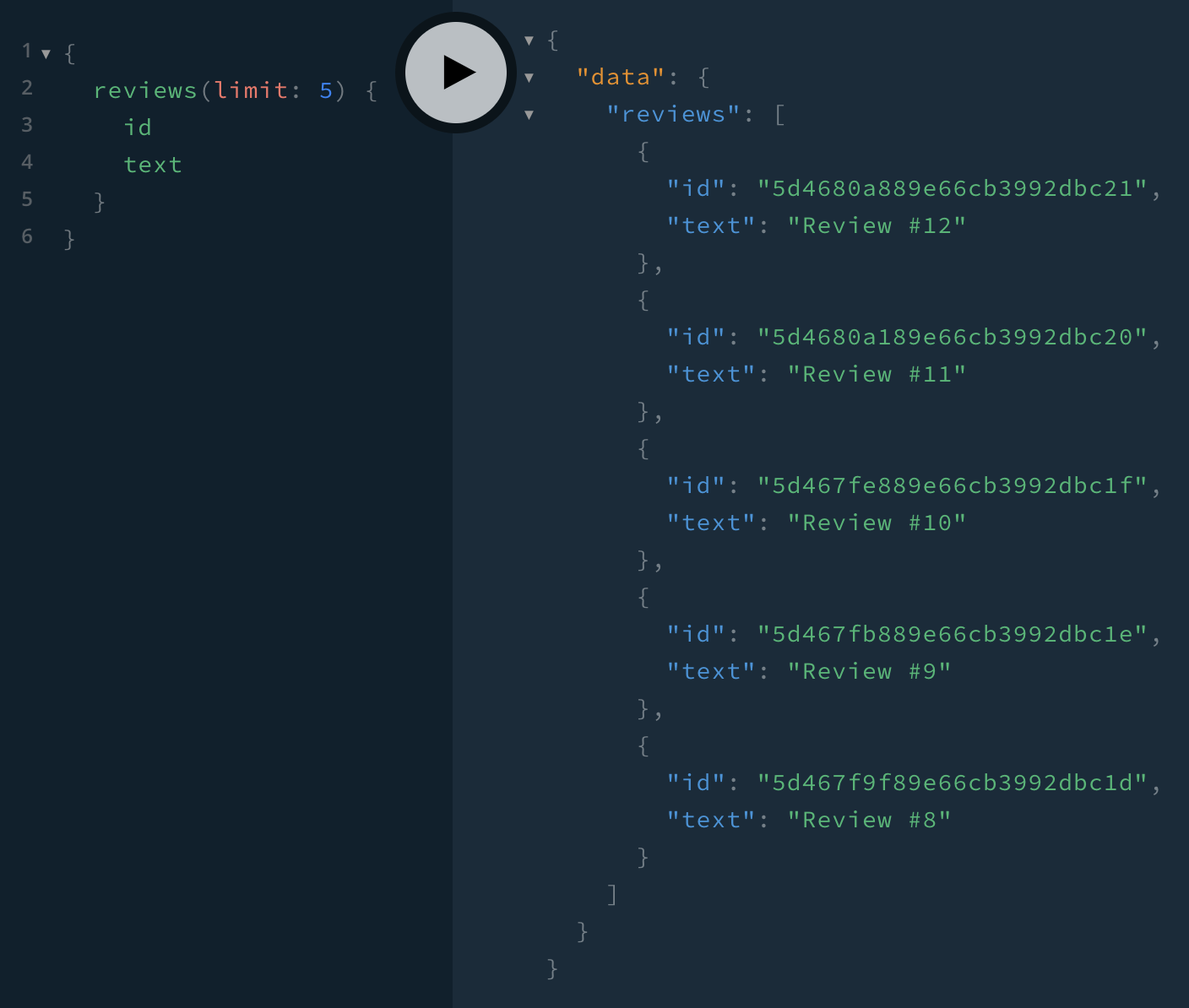
Then we take the last ID and use it for the after argument:
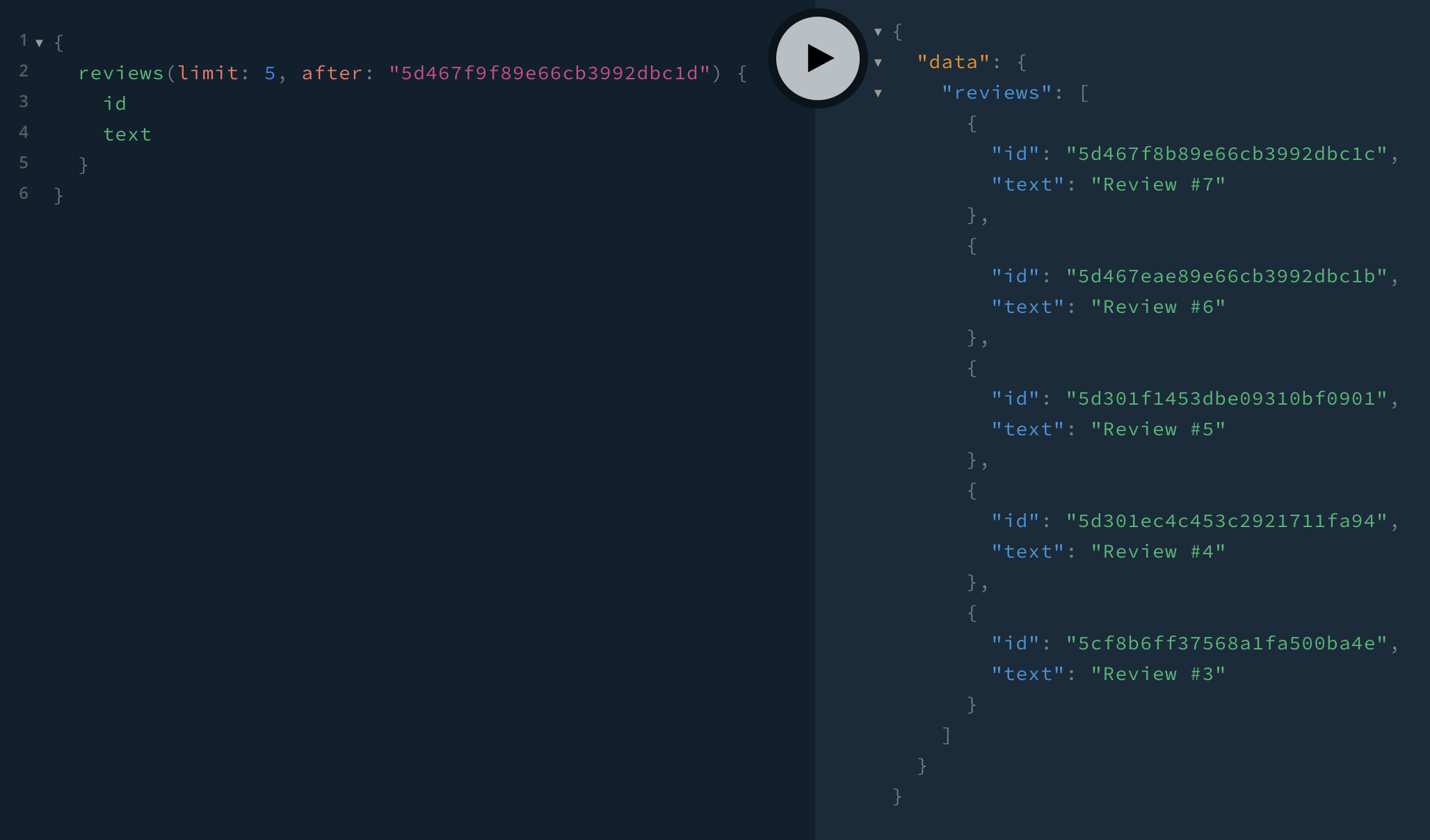
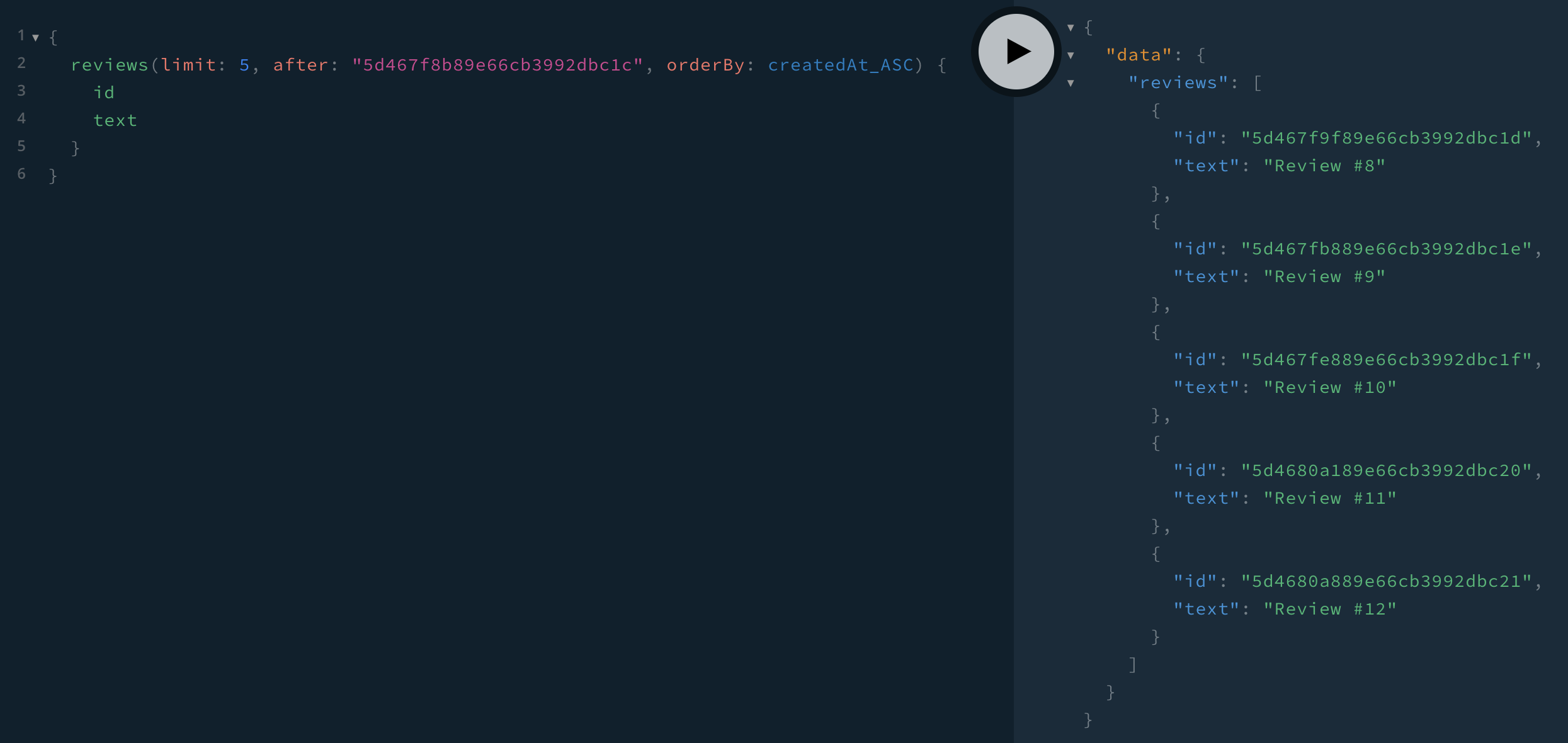
It works! If we wanted to paginate the other way from review #7, we would switch the orderBy:
Relay cursor connections
If you’re jumping in here,
git checkout pagination2_0.2.0(tag pagination2_0.2.0, or compare pagination2...pagination3)
Relay cursor connections are defined by the Relay Cursor Connections spec. It specifies a standard way of implementing cursor pagination so that different clients and tools (like the Relay client library) can depend on that specific schema structure. Its benefits over other cursor structures are listed at the end of the Cursors section above. Its cost is a more complex schema, like this one:
type ReviewEdge {
cursor: String!
node: Review
}
type PageInfo {
startCursor: String!
endCursor: String!
hasNextPage: Boolean!
hasPreviousPage: Boolean!
}
type ReviewsConnection {
edges: [ReviewEdge]
pageInfo: PageInfo!
totalCount: Int!
}
extend type Query {
reviews(first: Int, after: String, last: Int, before: String): ReviewsConnection!
}Including both first/after and last/before is optional—according to the spec, only one is required. Also, we can add fields—for instance, totalCount isn’t in the spec—and add arguments to Query.reviews (for instance, filtering and sorting arguments). Common added arguments include a filterBy object type and orderBy, which can be an enum as we’ve been doing or a list (for example orderBy: [stars_DESC, createdAt_ASC]). Let’s do just first/after, orderBy, and a single filter field—stars:
extend type Query {
reviews(first: Int, after: String, orderBy: ReviewOrderBy, stars: Int): ReviewsConnection!
}For implementing the resolver, first we check arguments:
export default {
Query: {
reviews: async (
_,
{ first = 10, after, orderBy = 'createdAt_DESC', stars },
{ dataSources }
) => {
const errors = {}
if (first !== undefined && first < 1) {
errors.first = `must be non-negative`
}
if (first > MAX_PAGE_SIZE) {
errors.first = `cannot be greater than ${MAX_PAGE_SIZE}`
}
if (stars !== undefined && ![0, 1, 2, 3, 4, 5].includes(stars)) {
errors.stars = `must be an integer between 0 and 5, inclusive`
}
if (!isEmpty(errors)) {
throw new InputError({ review: errors })
}
// … TODO
return {
edges,
pageInfo: {
startCursor,
endCursor,
hasNextPage,
hasPreviousPage
},
totalCount
}
}
},
...
}Then, after some work (which will include one or more calls to dataSources.reviews.*), we return an object matching the ReviewsConnection in our schema:
type ReviewsConnection {
edges: [ReviewEdge]
pageInfo: PageInfo!
totalCount: Int!
}Here’s how to construct that object:
import { encodeCursor } from '../util/pagination'
export default {
Query: {
reviews: async (
_,
{ first = 10, after, orderBy = 'createdAt_DESC', stars },
{ dataSources }
) => {
...
const {
reviews,
hasNextPage,
hasPreviousPagePromise
} = await dataSources.reviews.getPage({ first, after, orderBy, stars })
const edges = reviews.map(review => ({
cursor: encodeCursor(review),
node: review
}))
return {
edges,
pageInfo: {
startCursor: encodeCursor(reviews[0]),
endCursor: encodeCursor(reviews[reviews.length - 1]),
hasNextPage,
hasPreviousPage: hasPreviousPagePromise
},
totalCount: dataSources.reviews.getCount({ stars })
}
}
},dataSources.reviews.getPage() returns an object with three things. We use reviews to create the edges and cursors. Each field returned from a resolver can either be a value or a Promise that resolves to a value (Apollo Server will resolve the Promise for us if that field is selected in the query). Instead of a boolean for hasPreviousPage, we return a Promise. And for totalCount, we call a new data source method getCount():
export default class Reviews extends MongoDataSource {
getCount(filter) {
return this.collection.find(filter).count()
}
...
}The code for getPage() is a bit complex. We’ll make three database queries to fetch the list of reviews and determine whether there are next and previous pages:
import { decodeCursor } from '../util/pagination'
export default class Reviews extends MongoDataSource {
getPage({ first, after, orderBy, stars }) {
const isDescending = orderBy === 'createdAt_DESC'
const filter = {}
const prevFilter = {}
if (after) {
const afterId = decodeCursor(after)
filter._id = isDescending ? { $lt: afterId } : { $gt: afterId }
prevFilter._id = isDescending ? { $gte: afterId } : { $lte: afterId }
}
if (stars) {
filter.stars = stars
}
const sort = { _id: isDescending ? -1 : 1 }
const reviewsPromise = this.collection
.find(filter)
.sort(sort)
.limit(first)
.toArray()
const hasNextPagePromise = this.collection
.find(filter)
.sort(sort)
.skip(first)
.hasNext()
const hasPreviousPagePromise =
!!after &&
this.collection
.find(prevFilter)
.sort(sort)
.hasNext()
return { reviewsPromise, hasNextPagePromise, hasPreviousPagePromise }
}
...
}The reviews query has:
.limit(first)
.toArray()Whereas to see if there’s a next item, we do:
.skip(first)
.hasNext()And to check if there’s a previous item, we use the opposite filter ($gte and $lte are greater/less than or equal to) and hasNext():
prevFilter._id = isDescending ? { $gte: afterId } : { $lte: afterId }
...
this.collection
.find(prevFilter)
.sort(sort)
.hasNext()If the number of database queries became a performance problem, we could remove the need for the second by changing .limit(first) in the reviews query to .limit(first + 1). Then, if we receive first + 1 results, we know there’s a next page:
...
const reviews = await this.collection
.find(filter)
.sort(sort)
.limit(first + 1)
.toArray()
const hasNextPage = reviews.length > first
if (hasNextPage) {
reviews.pop()
}
const hasPreviousPagePromise =
!!after &&
this.collection
.find(prevFilter)
.sort(sort)
.hasNext()
return { reviews, hasNextPage, hasPreviousPagePromise }
}We do reviews.pop() to take the extra last review (which the client didn’t request) off the list.
Now we have a new issue: Our latency has gone up, since we’re making two database queries in serial (awaiting one before starting the other) instead of three queries in parallel (initiating them all at the same time). To fix this, we can create the hasPreviousPagePromise before the await:
const hasPreviousPagePromise =
!!after &&
this.collection
.find(prevFilter)
.sort(sort)
.hasNext()
const reviews = await this.collection
.find(filter)
.sort(sort)
.limit(first + 1)
.toArray()
const hasNextPage = reviews.length > first
if (hasNextPage) {
reviews.pop()
}
return { reviews, hasNextPage, hasPreviousPagePromise }
}If, however, we were more concerned with database load than latency, and clients frequently made reviews queries without selecting Query.reviews.pageInfo.hasPreviousPage, then we could make those queries only trigger a single database query. We can do this by moving hasPreviousPage from a property in an object returned by the Query.reviews resolver (what we’re currently doing) to a PageInfo.hasPreviousPage resolver:
…
const getHasPreviousPage = () =>
!!after &&
this.collection
.find(prevFilter)
.sort(sort)
.hasNext()
return { reviews, hasNextPage, getHasPreviousPage }
}And then we update the resolvers:
export default {
Query: {
reviews: async (
_,
{ first = 10, after, orderBy = 'createdAt_DESC', stars },
{ dataSources }
) => {
...
const {
reviews,
hasNextPage,
getHasPreviousPage
} = await dataSources.reviews.getPage({ first, after, orderBy, stars })
const edges = reviews.map(review => ({
cursor: encodeCursor(review),
node: review
}))
return {
edges,
pageInfo: {
startCursor: encodeCursor(reviews[0]),
endCursor: encodeCursor(reviews[reviews.length - 1]),
hasNextPage,
getHasPreviousPage
},
totalCount: dataSources.reviews.getCount({ stars })
}
}
},
PageInfo: {
hasPreviousPage: ({ getHasPreviousPage }) => getHasPreviousPage()
},
...
}Apollo Server first calls the Query.reviews resolver, which returns a ReviewsConnection that includes a PageInfo object without a hasPreviousPage property. Instead, Apollo Server will call the PageInfo.hasPreviousPage resolver. This resolver receives as its first argument the pageInfo sub-object that the resolver above returned, so it can call the getHasPreviousPage() function, which either immediately returns a boolean (when there’s no after argument) or initiates a database query and returns a Promise. If the hasPreviousPage field isn’t selected in the GraphQL query, the resolver won’t be called, and the database query won’t be sent.
Let’s try out a query:
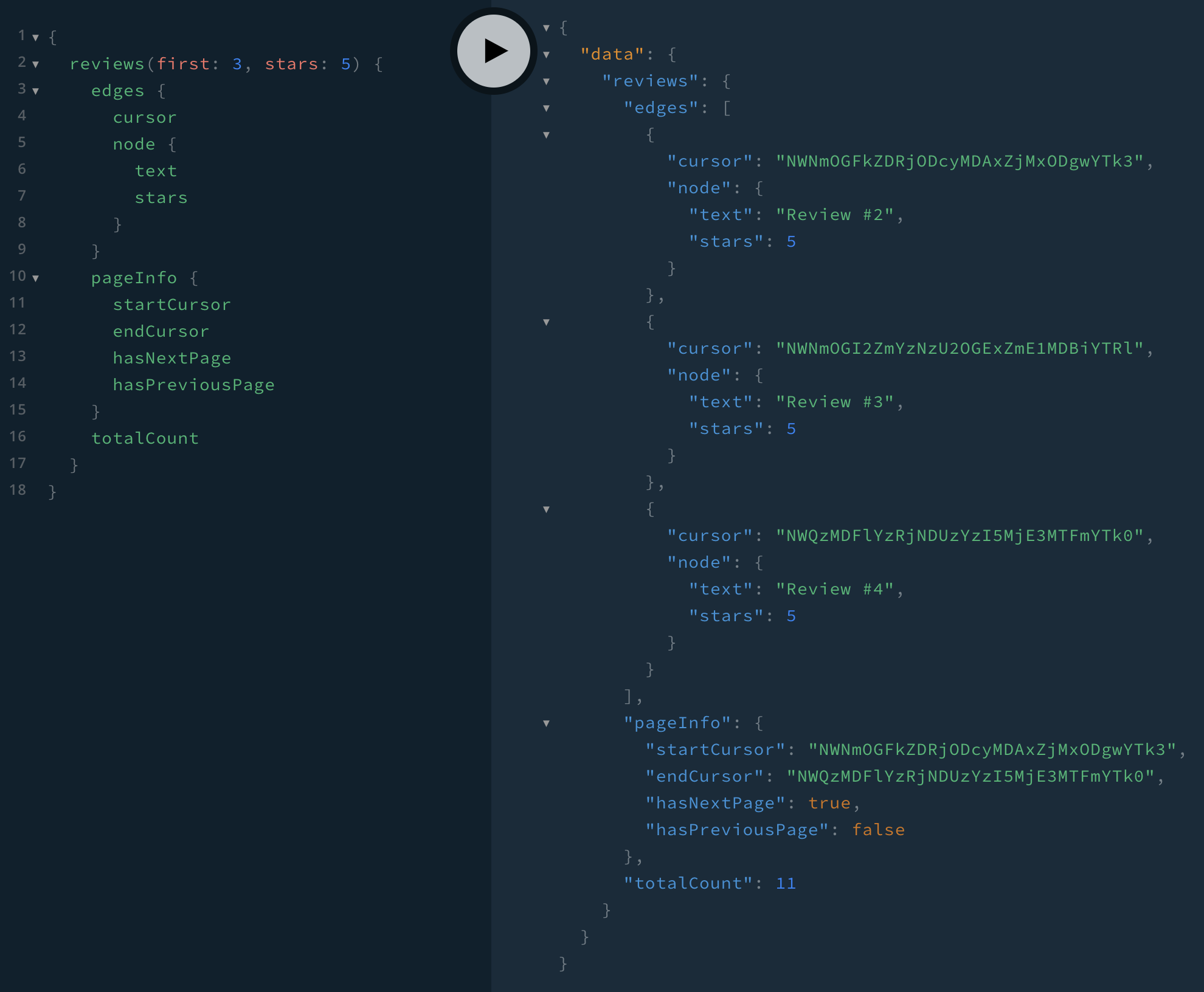
We see there are 11 total reviews with 5 stars, starting with review #2, and there are no previous pages (pageInfo.hasPreviousPage is false). If we want to request the next 3 reviews after review #4, we use pageInfo.endCursor as the next query’s after:
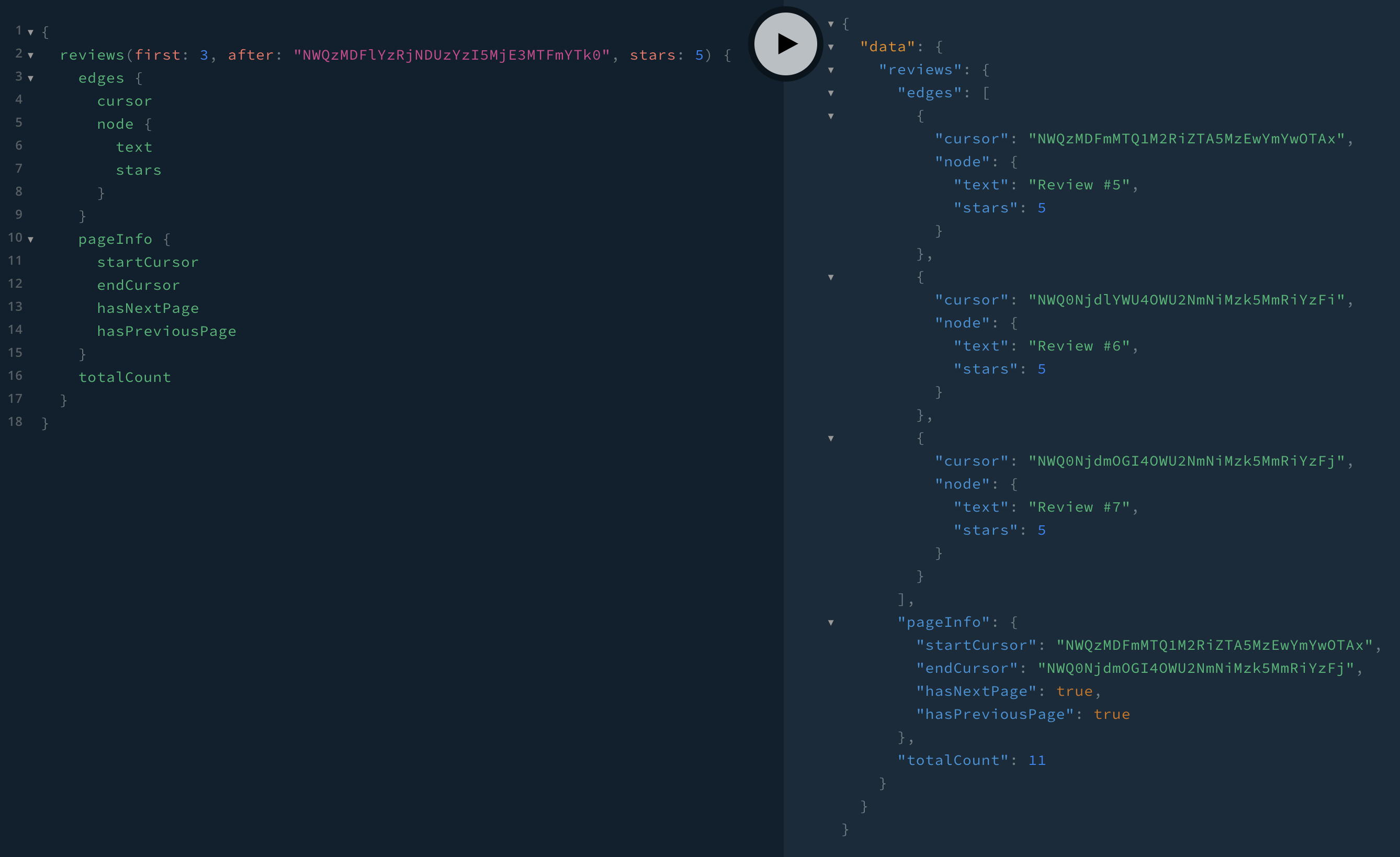
And we get reviews #5–7 💃☺️.
Lastly, let’s look at the cursor creating and decoding:
import { ObjectId } from 'mongodb'
export const encodeCursor = review =>
Buffer.from(review._id.toString()).toString('base64')
export const decodeCursor = cursor =>
ObjectId(Buffer.from(cursor, 'base64').toString('ascii'))We take the review’s _id property and base64-encode it, and then decode it back to an ASCII string, which we convert to an ObjectId.
Using _id works because we only support ordering by createdAt. If we had orderBy: updatedAt_DESC, then the cursor would need to contain the review’s updatedAt property. To differentiate between the two, we could encode an object instead of just an ID string:
export const encodeCursor = (review, orderBy) => {
const cursorData = ['updatedAt_DESC', 'updatedAt_ASC'].includes(orderBy)
? { updatedAt: review.updatedAt }
: { _id: review._id }
return Buffer.from(JSON.stringify(cursorData)).toString('base64')
}
export const decodeCursor = cursor =>
JSON.parse(Buffer.from(cursor, 'base64').toString('ascii'))Also, for either of our encoding systems to work, the client has to continue sending the orderBy and stars arguments (so that the server knows what MongoDB query filter and sort to use). If we wanted the client to be able to just send first and after, then we would need to encode the ordering and filtering arguments in cursors. Then the server could decode the information later when receiving a cursor as an after argument:
export const encodeCursor = (review, orderBy, stars) => {
const cursorData = {
_id: review._id,
updatedAt: review.updatedAt,
orderBy,
stars
}
return Buffer.from(JSON.stringify(cursorData)).toString('base64')
}