Hasura
To view this content, buy the book! 😃🙏
Or if you’ve already purchased.
Hasura
Hasura is a GraphQL-as-a-service company. In Deployment > Options, we covered IaaS, PaaS, and FaaS, which are different ways we can host our code. In GraphQL as a service, we don't have to write code—the server is automatically set up based on our configuration.
While it's true we don't have to write code, many apps need at least a little custom logic, so there are various ways to write our own code or SQL statements and integrate them into our Hasura server's functioning. These ways—which we'll get to later in this section—include actions, triggers, functions, and remote schemas.
Here are the pros and cons of using Hasura instead of coding a server ourselves:
Pros
- Build faster: We trade writing a lot of code for learning simple configuration settings and writing a little code here and there. As we can see by looking at this long Chapter 11 of the Guide, there are a lot of pieces that go into even a small production-ready GraphQL server, and Hasura does most of those for us.
- Performs better: If we write the whole server ourselves, we'd have bugs and performance issues. Hasura has a very performant design (more on that later), and most bugs have been found and worked out already by current users of the platform.
- No lock-in: We're not dependent on Hasura Inc., the company that created Hasura, to run our server. The code is open source and can easily be deployed to Heroku or any cloud provider that supports Docker containers. This is a benefit over other closed-source provider-hosted BaaS's, like Firebase and Parse.
Cons
- Less flexibility: While Hasura has many different features and ways to customize its behavior (which for the majority of applications are sufficient), there are some things we just wouldn't be able to do unless we broke into the code of Hasura itself (like adding a new Postgres type).
- Future uncertainty: While Hasura Inc. has a lot of funding and customers, it is a startup with an uncertain future. If it goes out of business, updates will fall to the open-source community, which would inevitably be less productive and proactive. And when we have problems, we'll no longer be able to go to the company's support channel of experts in the platform—we'll have to file an issue or post to Stack Overflow and hope the community responds, or dig into the platform code ourselves.
- Non-monolithic: If we want to use a monolithic server architecture and Hasura, we’re out of luck—Hasura forces an architecture based on microservices and serverless functions. In this section, we'll use Hasura to create a GraphQL API similar to the Guide API we coded earlier. We'll start out with our users and reviews data in the format we used in the SQL section, generate CRUD queries and mutations, and then go through modifications to match the Guide API. Through this process, we'll see how much less work it takes to build with Hasura than with code.
The first step is to deploy a Hasura server.
When this section was written, we deployed with Heroku, but since then, Hasura Cloud has been released, which is easier to use. Deployment instructions are here. After deploying, the rest of this section remains the same no matter where Hasura is hosted.
The "Deploy to Heroku" button on this page takes us to:
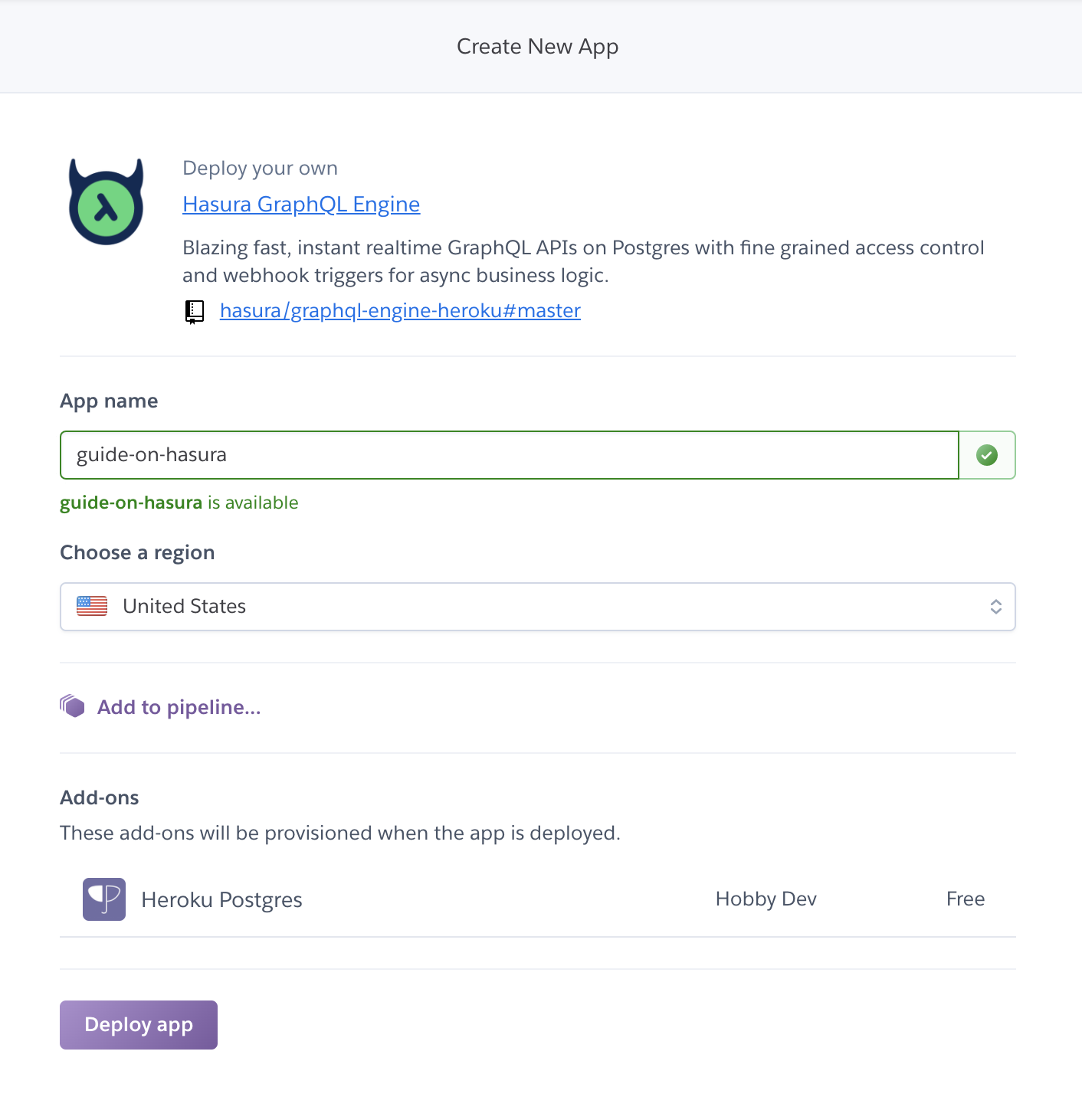
where we enter a name for our app and click "Deploy app." Once it's done, we get a deployment URL in the form of [app name].herokuapp.com, and when we visit /console, we see:
https://guide-on-hasura.herokuapp.com/console
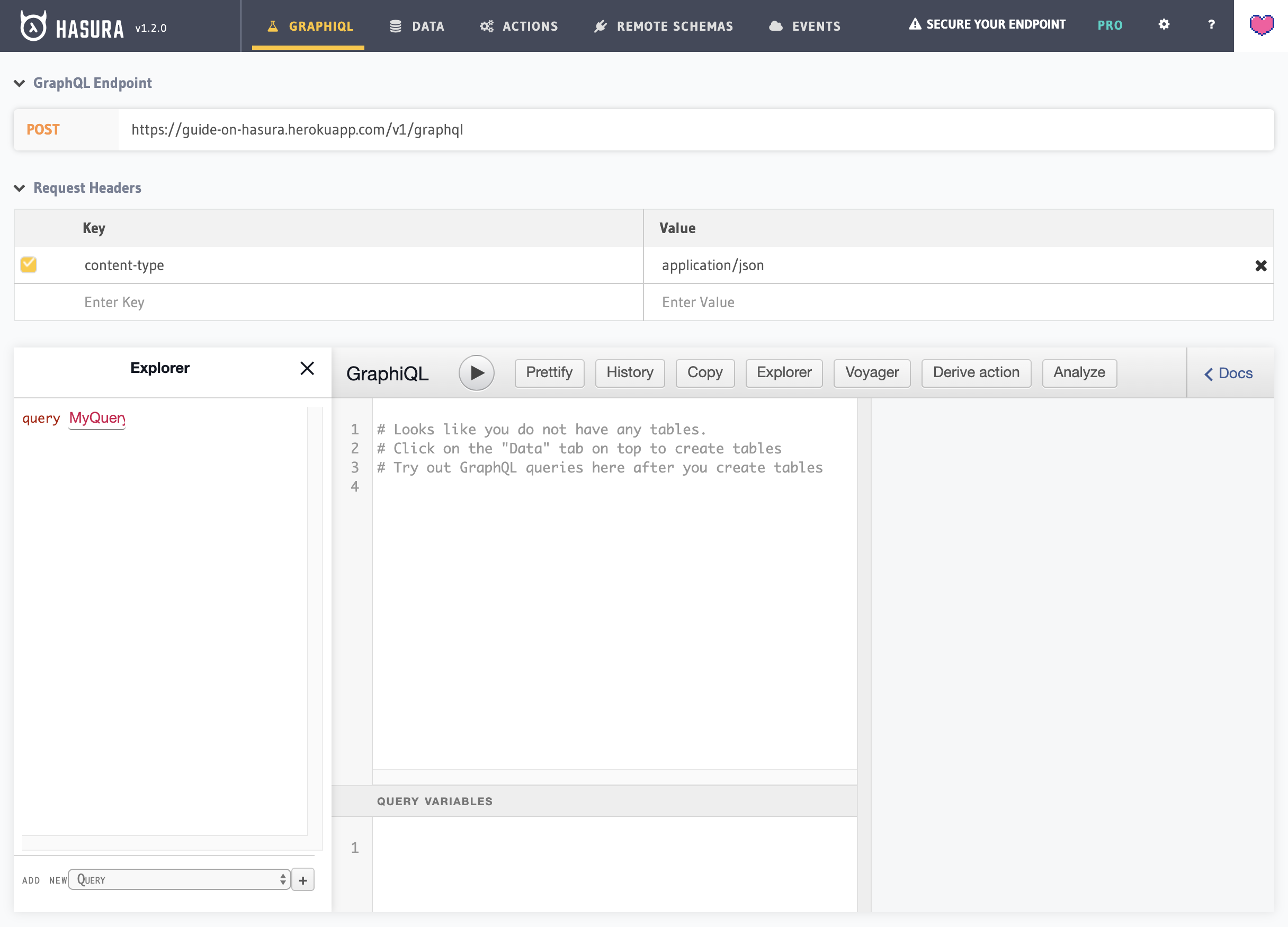
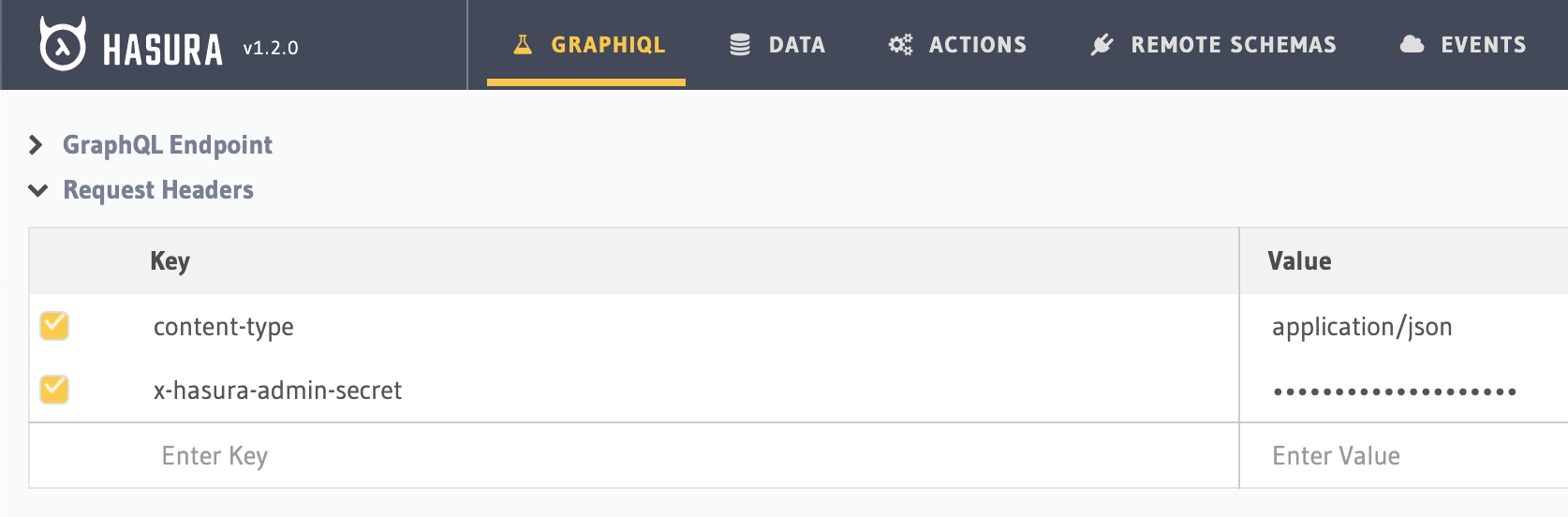
The first tab is GraphiQL, pointed at our endpoint, /v1/graphql. We can click the "Secure your endpoint" link on the top right to create an admin secret key, which we add as a request header named x-hasura-admin-secret:
The second tab is our SQL table schemas. Currently, we don't have any tables:
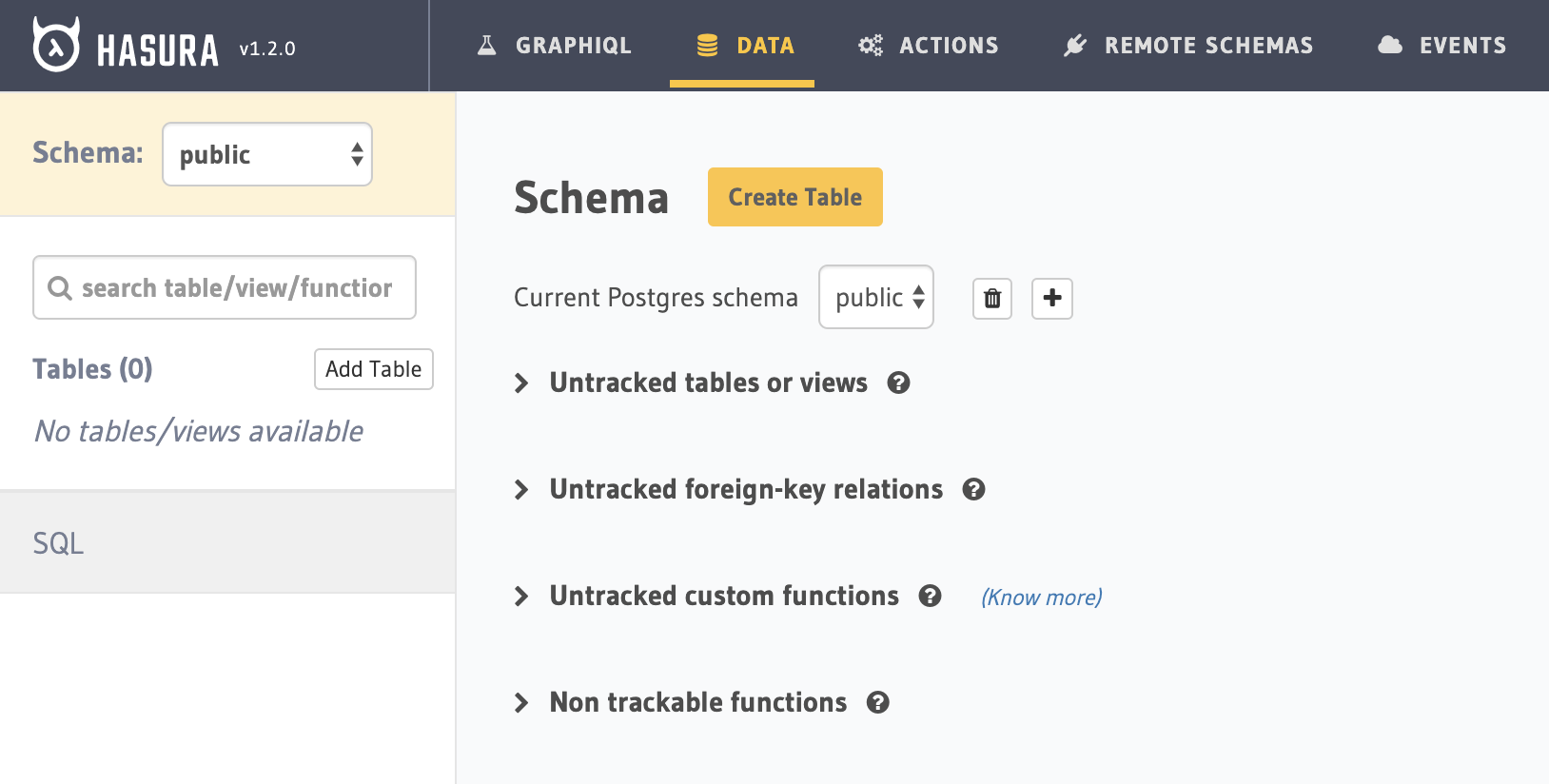
We can create tables in any of these ways:
- Through the web console's data tab, by clicking "Create Table."
- Connecting to an existing PostgreSQL database and selecting which tables we want Hasura to use.
- Generating tables and importing data from a JSON file.
Let's do the third, taking the data from our SQLite database in the SQL section:
db.json
{
"user": [
{
"id": 1,
"first_name": "John",
"last_name": "Resig",
"username": "jeresig",
"email": "[email protected]",
"auth_id": "github|1615"
}
],
"review": [
{
"id": 1,
"text": "Passable",
"stars": 3,
"author_id": 1
},
{
"id": 2,
"text": "Breathtaking 😍",
"stars": 5,
"author_id": 1
},
{
"id": 3,
"text": "tldr",
"stars": 1,
"author_id": 1
}
]
}We use the json2graphql command-line tool to do the importing:
$ npm install -g json2graphql
$ json2graphql https://guide-on-hasura.herokuapp.com --db ./db.json When complete, we see six root Query fields in GraphiQL Explorer:
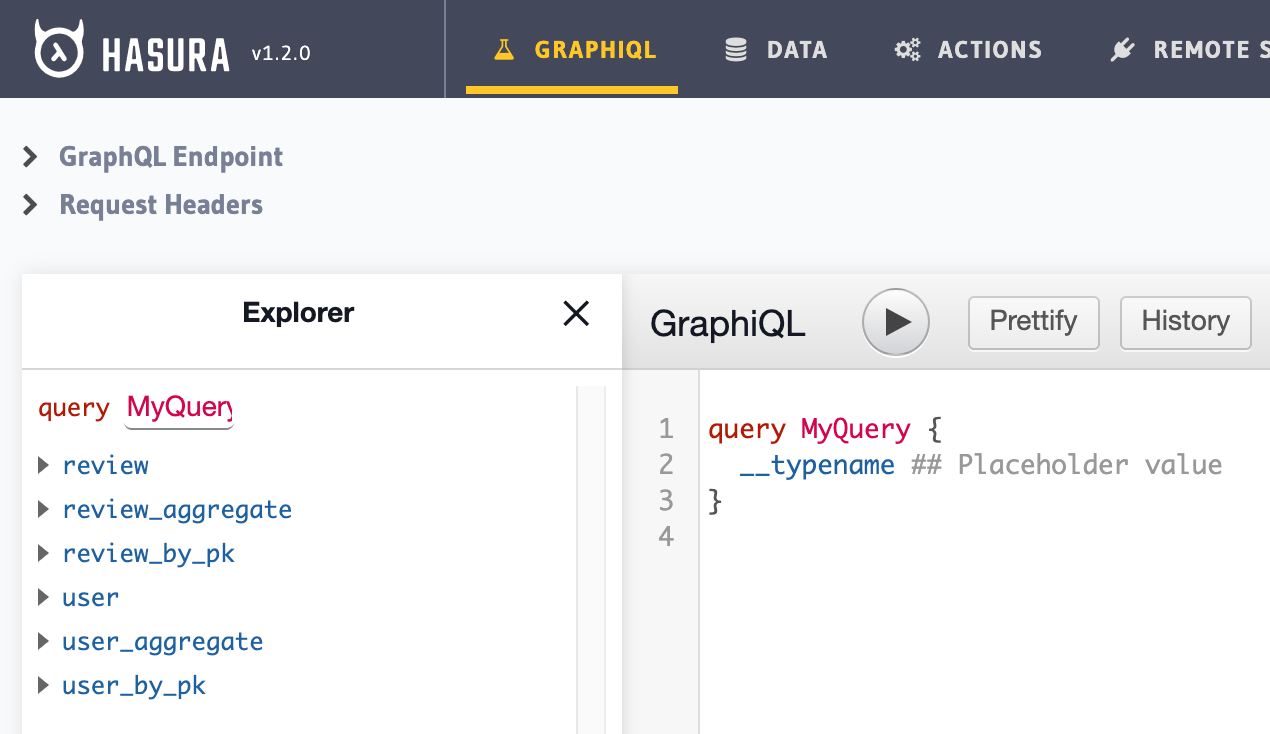
reviewreturns a list of reviews that can be:review_aggregateis for running aggregation functions like count, sum, avg, max, min, etc.review_by_pkretrieves a single review by its primary key (in this case,id).
The other three queries do the same for users.
In the Data tab, we see two SQL tables with columns and data matching our JSON:
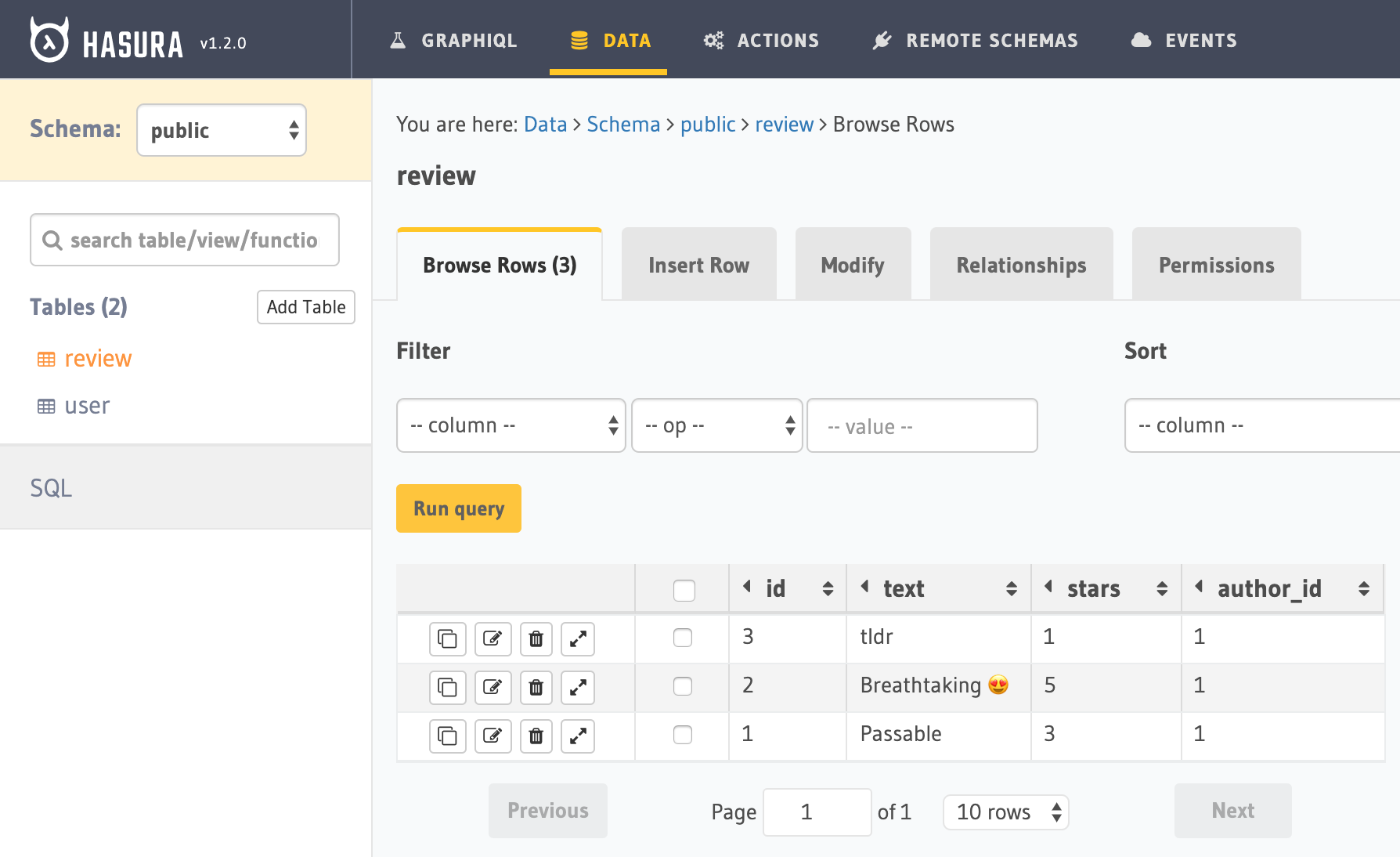
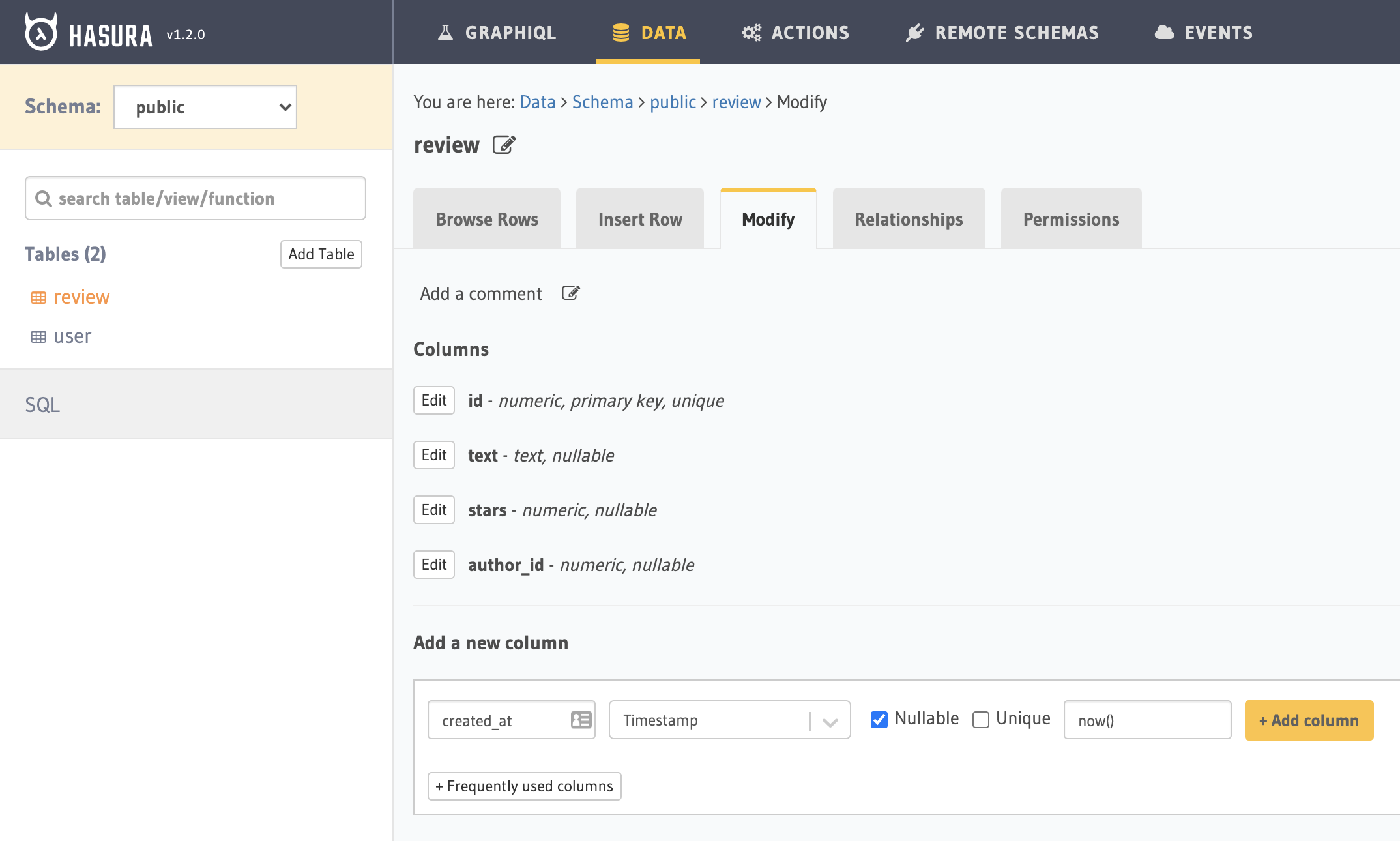
We're missing the created_at column—let's add it. We click the "Modify" tab and under "Add a new column," click “Frequently used columns”, created_at, and “Add column.”
Other possible default values for columns are SQL functions (a.k.a. stored procedures) and presets based on the current user's role.
Now we have a created_at field:
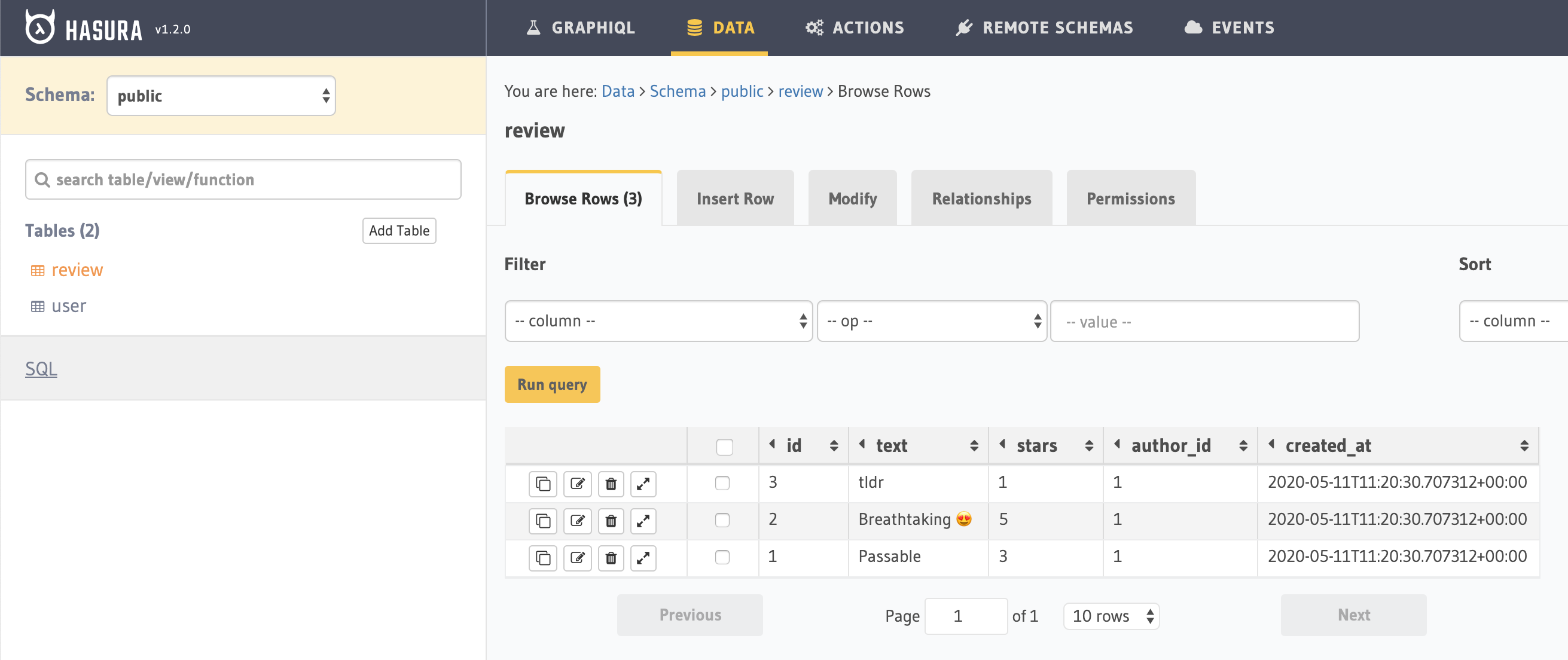
All our rows have the same created_at—the time at which we added the column. But future rows will have the time of insertion. We can test it out with an insert_review mutation, which we can find in the GraphiQL Explorer by selecting "Add new Mutation" in the bottom left corner and clicking the + button:
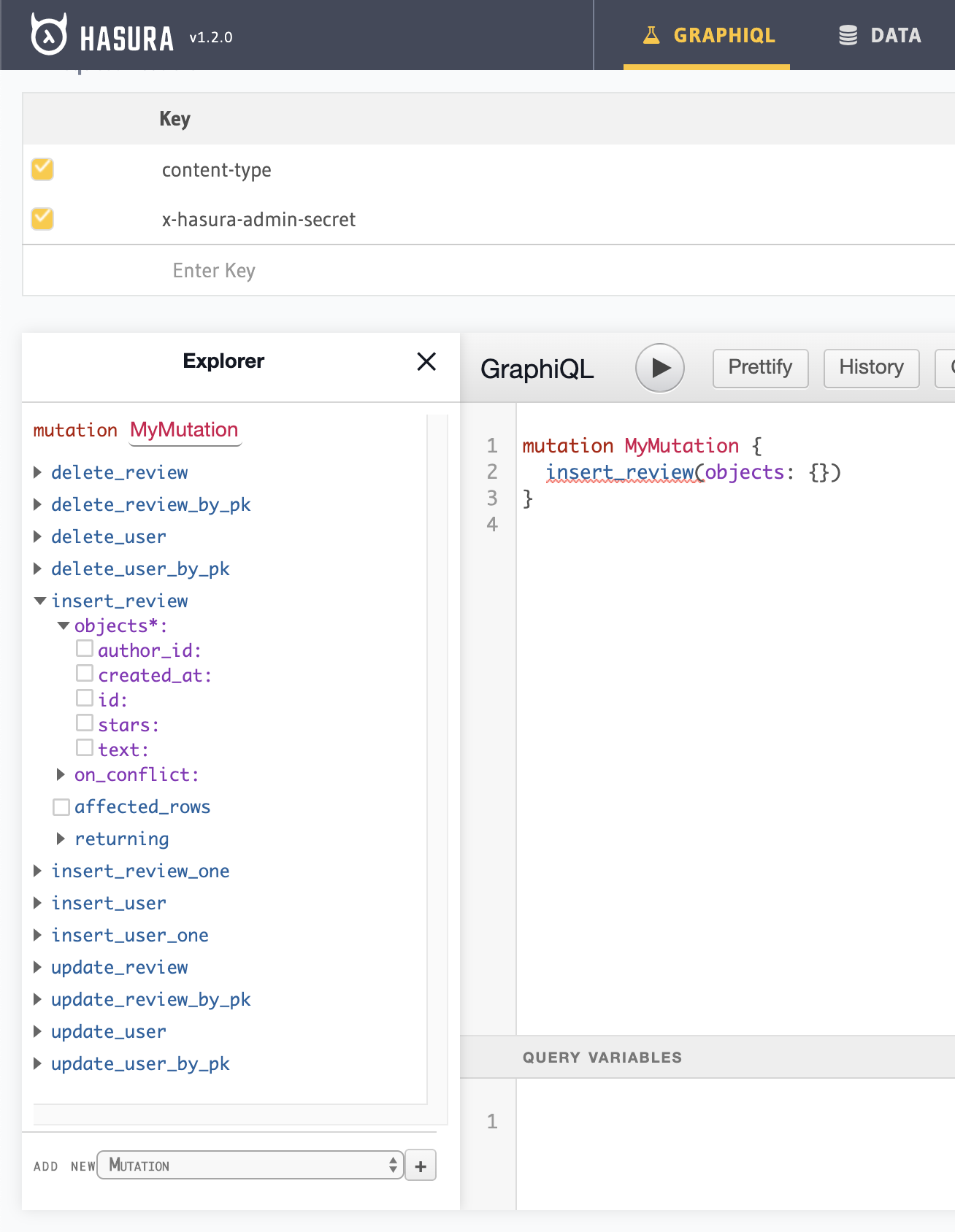
We also see the arguments, which are all the columns of a review. However, we don't want the client to decide author_id or created_at, so let's look at review permissions: Select Data tab, review table, Permissions tab. Right now, we have the admin role, but we can create a user role for all our users to have. We click the "x" in the insert column to edit insert permissions:
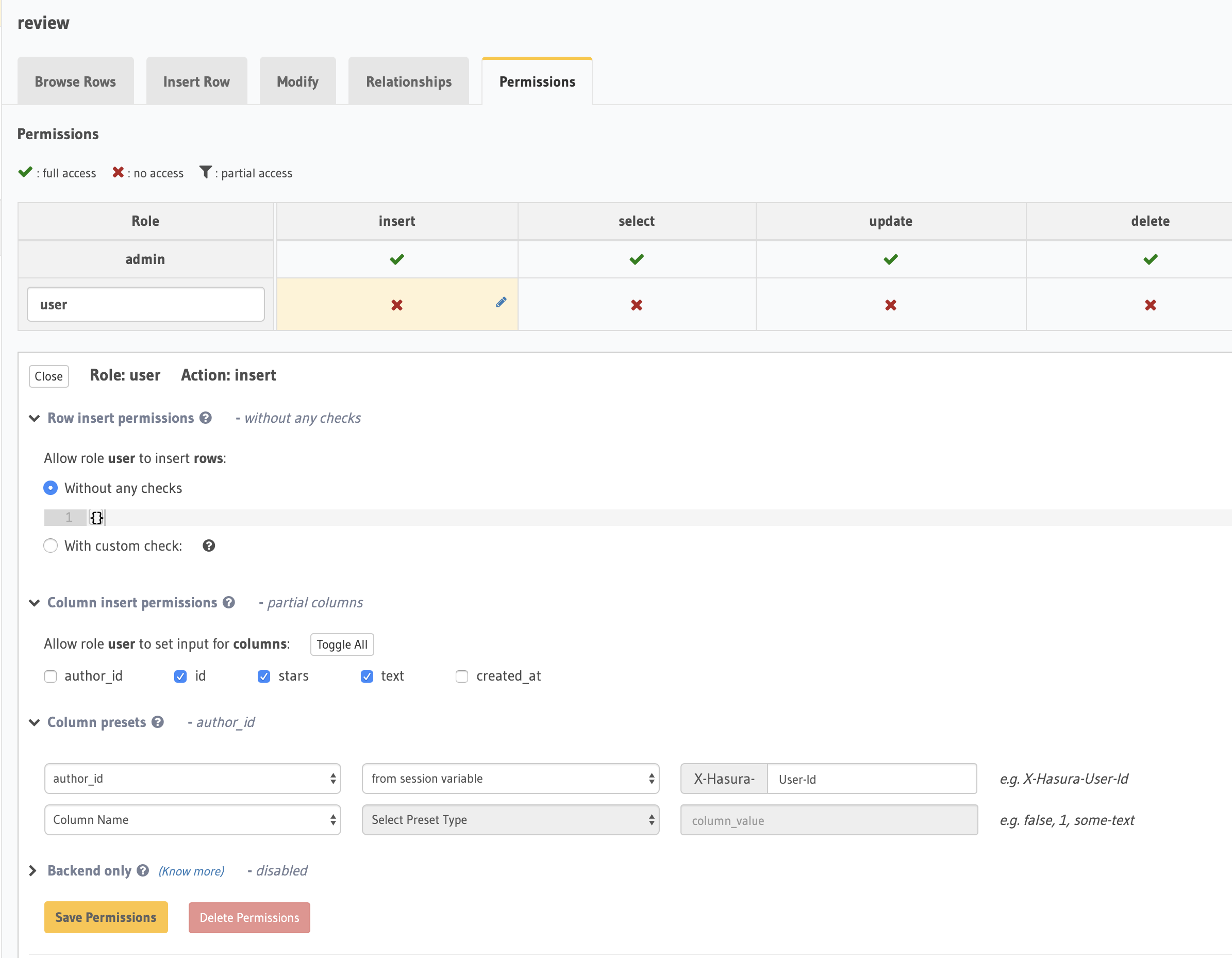
Under "Column insert permissions," we select id, stars, and text. (Normally, id would be auto incrementing, but we took a shortcut with json2graphql, which doesn't generate auto incrementing ids.) We need to set the value of author_id to the current user's ID, which will be stored in the X-Hasura-User-Id session variable. We can set session variables by setting request headers in GraphiQL, and in production, they're decoded from the JWT or session ID.
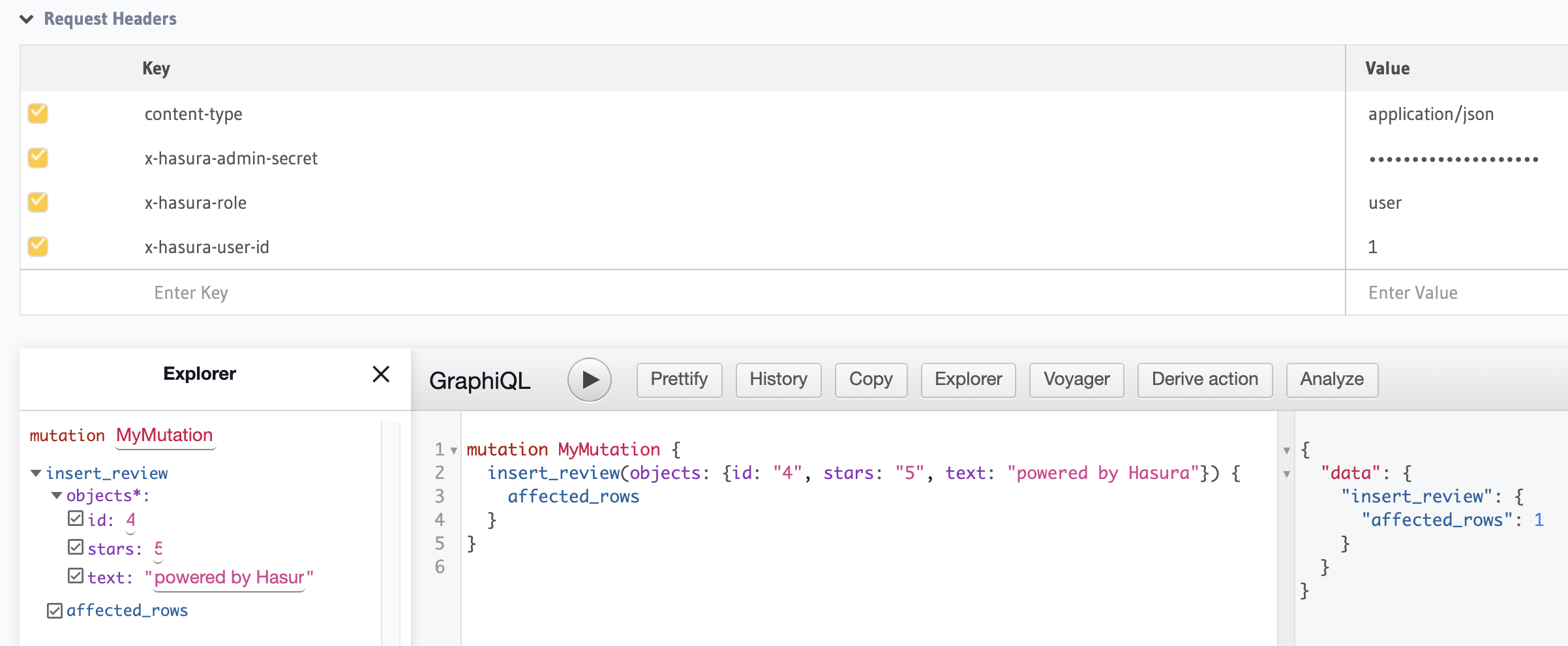
After clicking "Save Permissions," we can add the user ID and role (via x-hasura-role) to our request headers and see our mutation list change. Now insert_review is our only option. We can fill in all the arguments and run our mutation:
We can view our new review in the Data tab by changing our role to admin and making a review query:
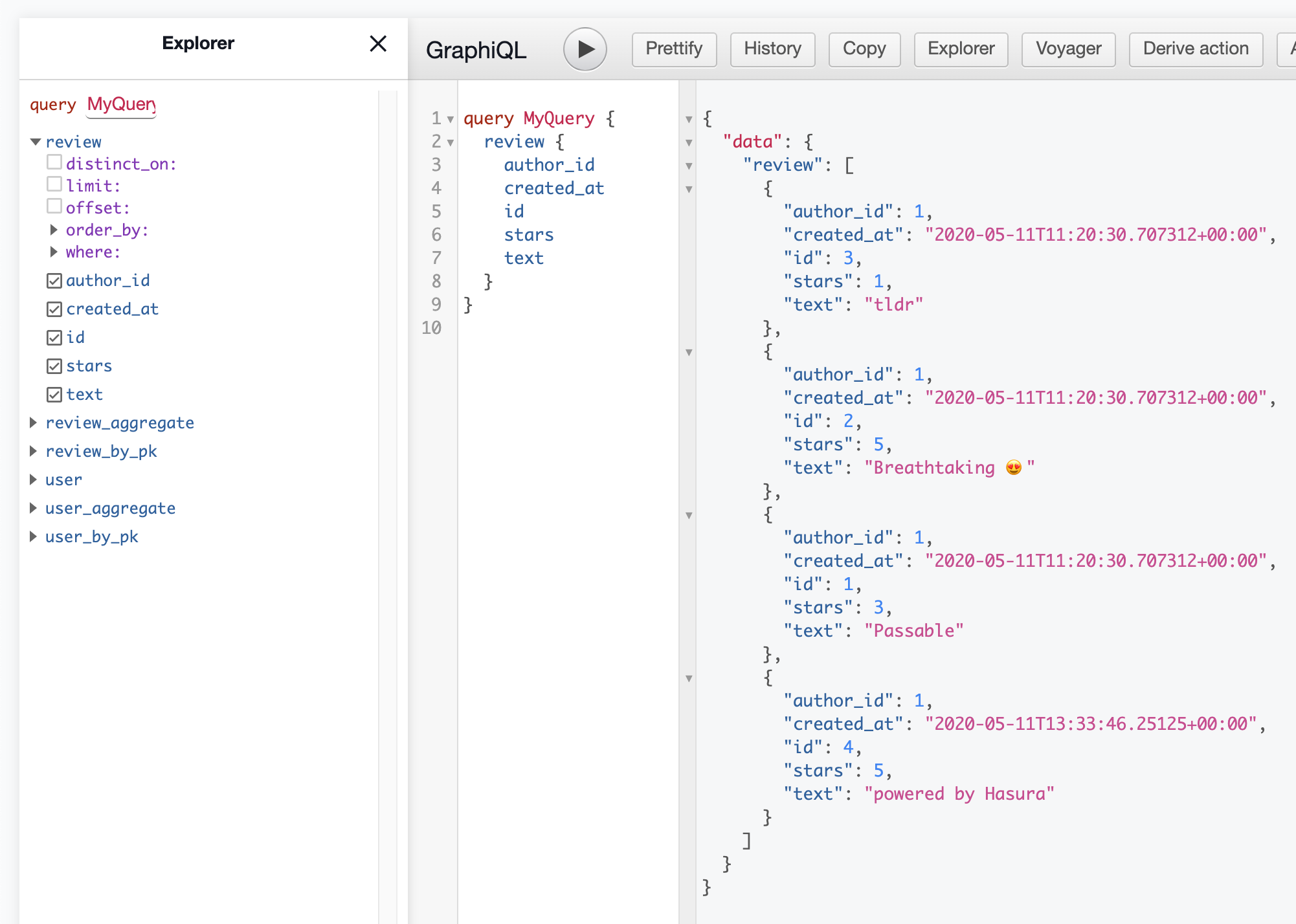
We can see the author_id and created_at fields were set correctly 😊.
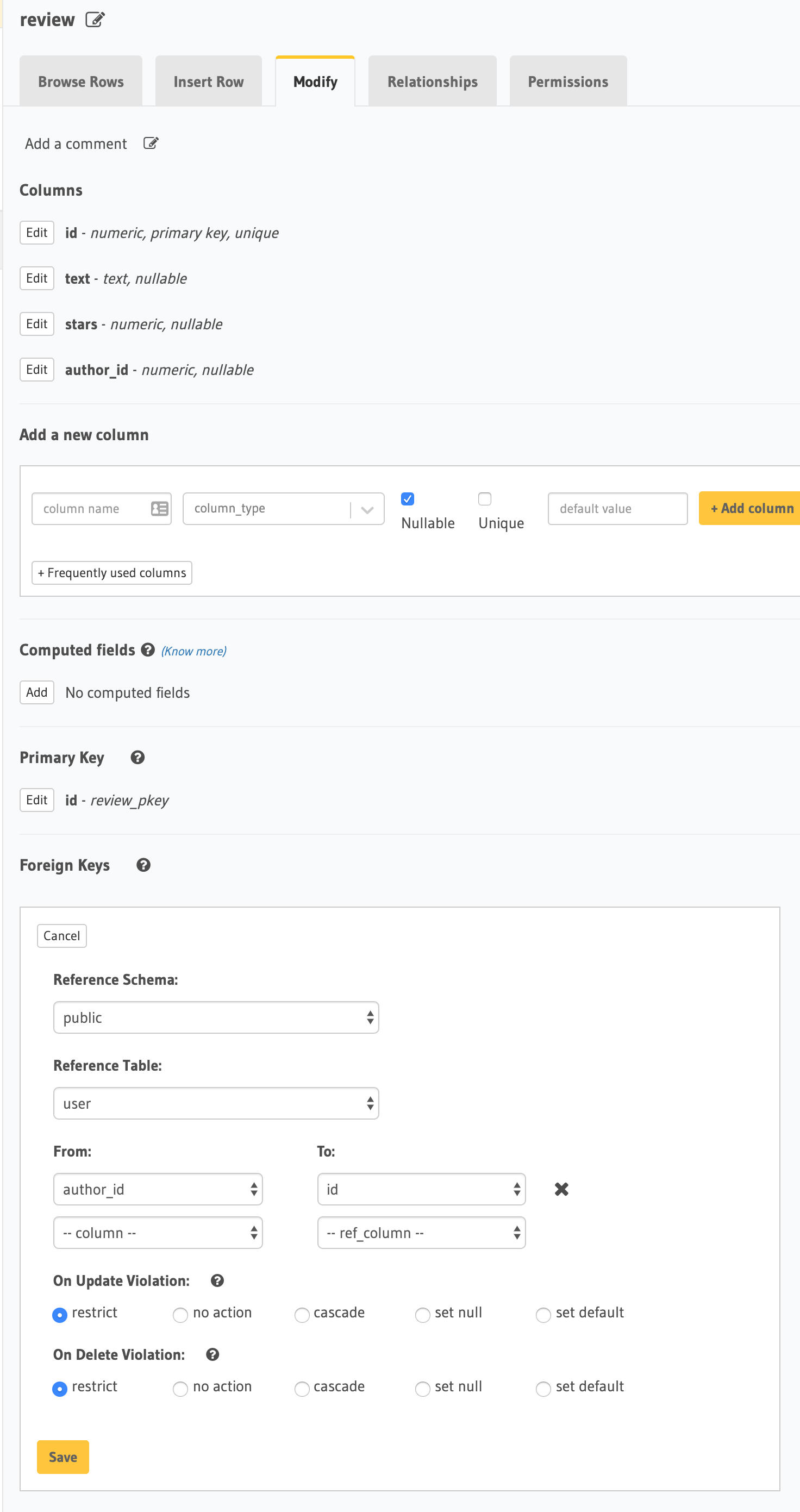
We might notice that now there's no review.author field, just a review.author_id. We can fix this by changing the author_id column to a foreign key and adding a "relationship." In the review table Modify tab, under Foreign Keys, we say that author_id references id in the user table:
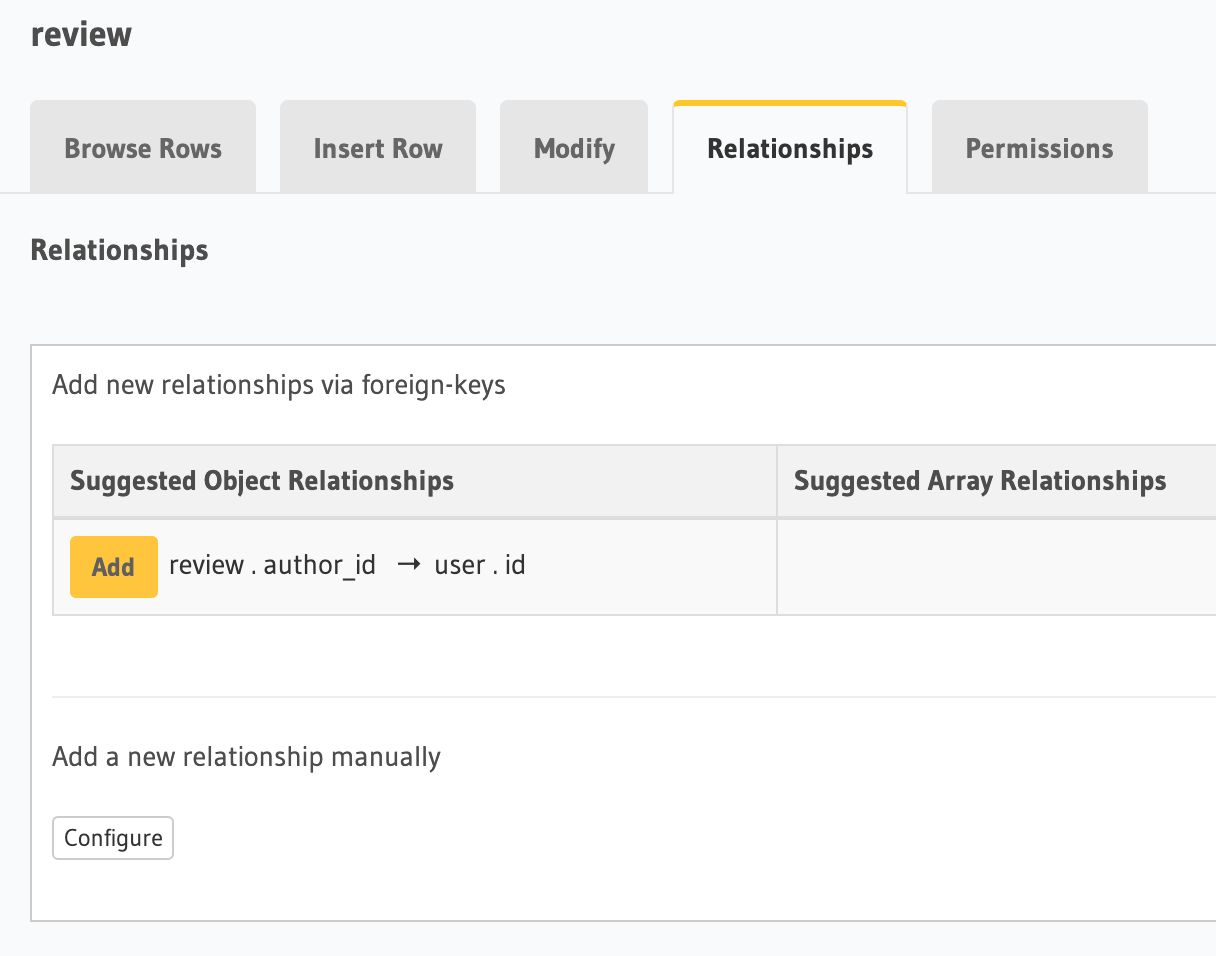
Then in the Relationships tab, we click the "Add" button and name the field author:
Now we can select the author field:
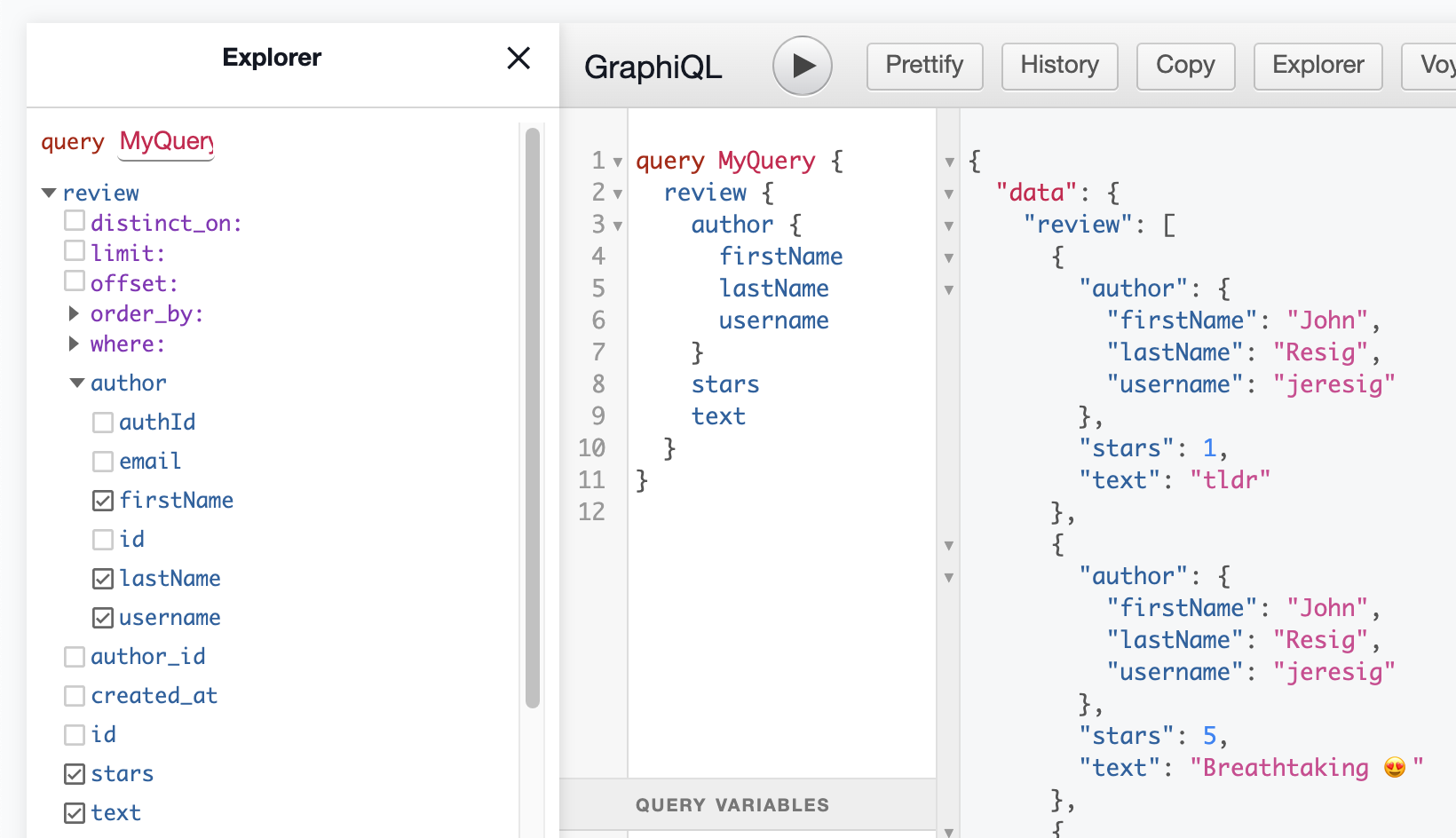
We can see that Hasura automatically translated the first_name SQL field to a firstName GraphQL field, and we can also customize field names as we wish.
If we wanted to prevent users from selecting the user.email field, we would go to the Permissions tab of the user table, add a row for the user role, and edit the "select" cell.
The Guide API has a searchUsers query:
type Query {
searchUsers(term: String!): [UserResult!]!
}We can do this with the user query and its where argument. If we expand it, we can see a list of allowed operators. _like uses the Postgres LIKE, so we can use '%term%':
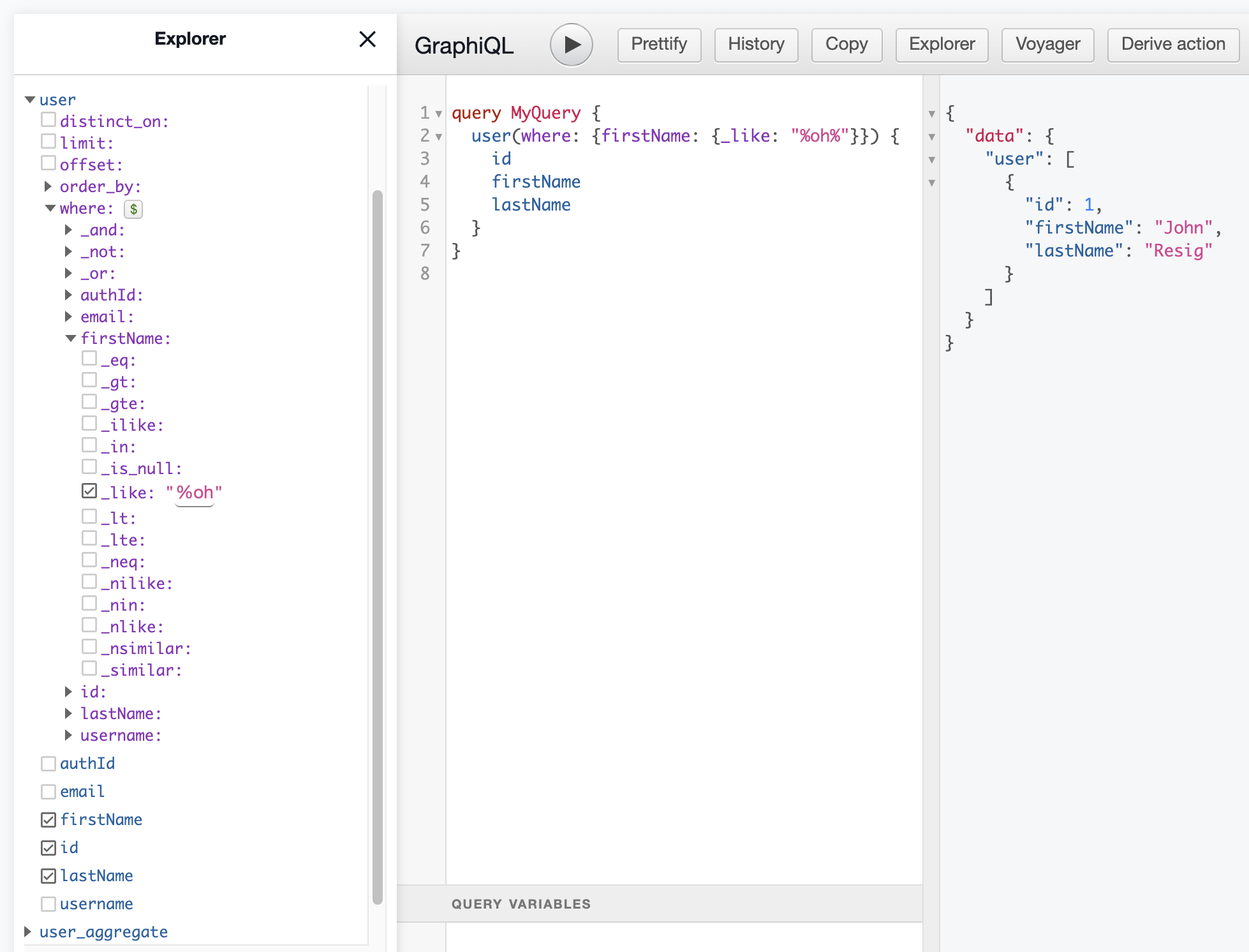
'%oh%' matches John, so we get the user object in the response.
So far, we've just used the automatically generated queries and mutations, but we can also create our own with actions. We go to the Actions tab, click "Create", and:
- Define a new Query or Mutation.
- Define any new types mentioned.
- Fill in the Handler URL.
- Click "Create."
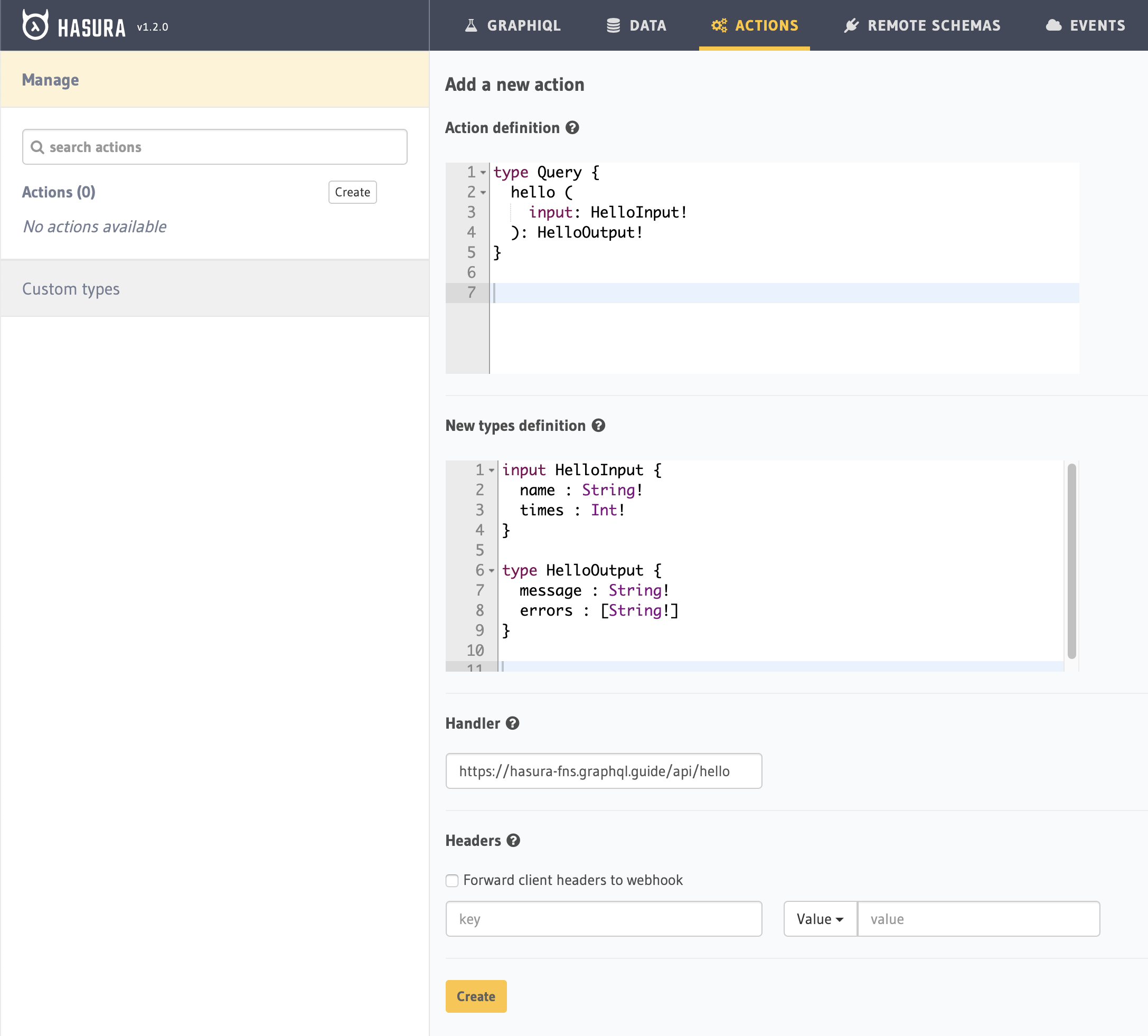
type Query {
hello (
input: HelloInput!
): HelloOutput!
}input HelloInput {
name : String!
times : Int!
}
type HelloOutput {
message : String!
errors : [String!]
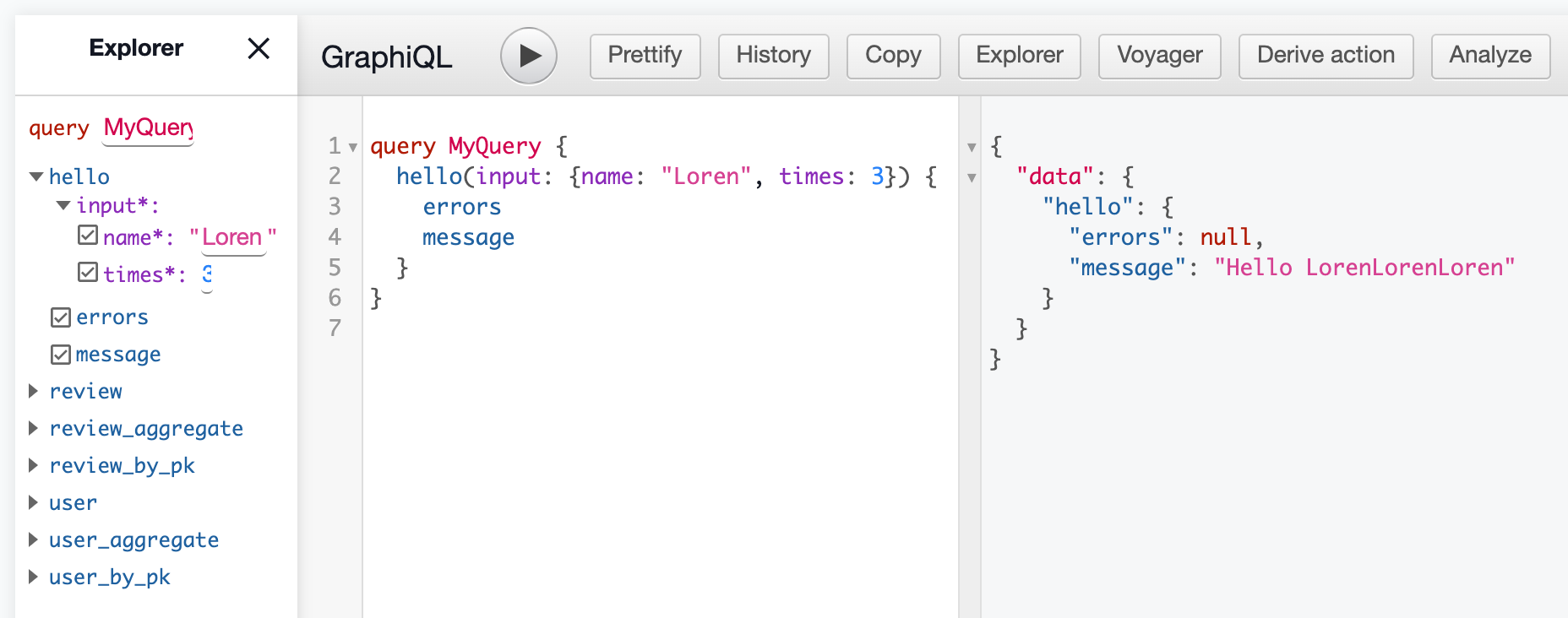
}A handler is like a resolver: It's an HTTP endpoint that's given the arguments and returns the response object. When a client makes the hello query, Hasura makes a POST request to the handler with a body like this:
{
session_variables: { 'x-hasura-role': 'user', 'x-hasura-user-id': '1' },
input: { input: { name: 'Loren', times: 3 } },
action: { name: 'hello' }
}Our code has to give a JSON response matching the HelloOutput type:
module.exports = (req, res) => {
const {
input: { name, times },
} = req.body.input
res.status(200).json({
message: `Hello ${name.repeat(times)}`,
errors: null,
})
}We can see it working in GraphiQL:
Here are some more Hasura features:
- Actions are HTTP endpoints that contain custom business logic. They can be used for creating custom queries and mutations, validating data, or enriching data.
- Validating mutation arguments with one or more of these methods:
- Postgres check constraints or triggers
- Hasura permissions
- Actions (when validation requires complex business logic or data from external sources)
- Subscriptions for either receiving changes to a field or additions/alterations to a list
- Triggers that call HTTP endpoints whenever data in Postgres changes
- Request transactions: If multiple mutations are part of the same request, they are executed sequentially in a single transaction. If any mutation fails, all the executed mutations will be rolled back.
- Many-to-many relationships: Connections between object types that are based on a join table.
- Views: Postgres views exposing the results of a SQL query as a virtual table.
- SQL functions that can be queried as GraphQL queries or subscriptions.
- Remote Schemas: Adding queries and mutations from other GraphQL APIs to our Hasura schema
- Remote Joins: Joining related data across tables and remote data sources.
These are some of the reasons why Hasura performs so well:
- Converts each operation into a single SQL statement with precise SELECTing and JOINs (similar to Join Monster)
- Transforms SQL statement results into GraphQL response data inside Postgres using JSON aggregation functions
- Uses Postgres prepared statements, which decrease response times by 10-20%.
- Uses Haskell and its warp HTTP stack, which both have great performance
- Powers subscriptions with polling, which scales to high write loads
Hasura Pro is a paid version of Hasura that includes:
- Analytics, which are helpful for finding slow queries and seeing errors in real time.
- Rate limiting. We can set limits based on:
- Number of requests per minute
- Query depth
- Allow-listing (safelisting): Accept only a preset list of operations.
- Regression testing: Automatically replay production traffic onto dev/staging.