Paginating
Four different ways of implementing pagination in GraphQL
To view this content, buy the book! 😃🙏
Or if you’ve already purchased.
Paginating
Our ReviewsQuery currently has limit: 20 because loading all the reviews would be unwise 😄. We don’t know how many reviews there will be in the database, and receiving thousands of them over the network would take a long time on mobile. They’d take a lot of memory in the Apollo cache, they’d take a long time to render onto the page, and we’d have the problems that come along with a high DOM (and VDOM) node count: interacting with the DOM takes longer, and the amount of memory the browser uses grows—in the worst case, it exceeds the available memory on the device. On mobile, the OS kills the browser process, and on a computer, the OS starts using the hard drive for memory, which is very slow.
😅 So! In any app where the user might want to see a potentially long list of data, we paginate: we request and display a set amount of data, and when the user wants more (either by scrolling down—in the case of infinite scroll—or by clicking a “next page” link or “page 3” link), we request and display more. There are two main methods of pagination: offset-based, which we’ll talk about first, and cursors.
We can display the data however we want. The two most common methods are pages (with next/previous links and/or numbered page links like Google search results) and infinite scroll. We can use either data-fetching method with either display method.
Offset-based
Offset-based pagination is the easier of the two methods to implement—both on the client and on the server. In its simplest form, we request a page number, and each page has a set number of items. The Guide server sends 10 items per page, so page 1 has the first 10, page 2 has items 11-20, etc. A more flexible form is using two parameters: offset (or skip) and limit. The client decides how large each page is by setting the limit of how many items the server should return. For instance, we can have 20-item pages by first requesting skip: 0, limit: 20, then requesting skip: 20, limit: 20 (“give me 20 items starting with #20”, so items 20-39), then skip: 40, limit: 20, etc.
The downside of offset-based pagination is that if the list is modified between requests, we might miss items or see them twice. Take, for example, this scenario:
- We fetch page 1 with the first 10 items.
- Some other user deletes the 4th and 5th items.
- If we were to fetch page 1 again, we would get the new first 10 items, which would now be items 1–3 and 6–12. But we don’t refetch page 1—we fetch page 2.
- Page 2 returns items 13–22. Which means now we’re showing the user items 1-10 and 13-22, and we’re missing items 11 and 12, which are now part of page 1.
On the other hand, if things are added to the list, we’ll see things twice:
- We fetch page 1 with the first 10 items.
- Some other user submits two new items.
- If we were to fetch page 1 again, we would get the 2 new items and then items 1–8. But instead we fetch page 2.
- Page 2 returns items 9-18, which means our list has items 9 and 10 twice—once from page 1 and once from page 2.
Depending on our application, these issues might never happen, or if they do, it might not be a big deal. If it is a big deal, switching to cursor-based pagination will fix it. Another possible solution, depending on how often items are added/deleted, is requesting extra pages (to make sure not to miss items) and de-duplicating (to make sure not to display the same item twice). For example, first we could request just page 1, and then when we want page 2, we request both pages 1 and 2. Now if we were in the first scenario above, and the 4th and 5th items were deleted, re-requesting page 1 would get items 11 and 12, which we previously missed. We’ll get items 1–3 and 6–10 a second time, but we can match their IDs to objects already in the cache and discard them.
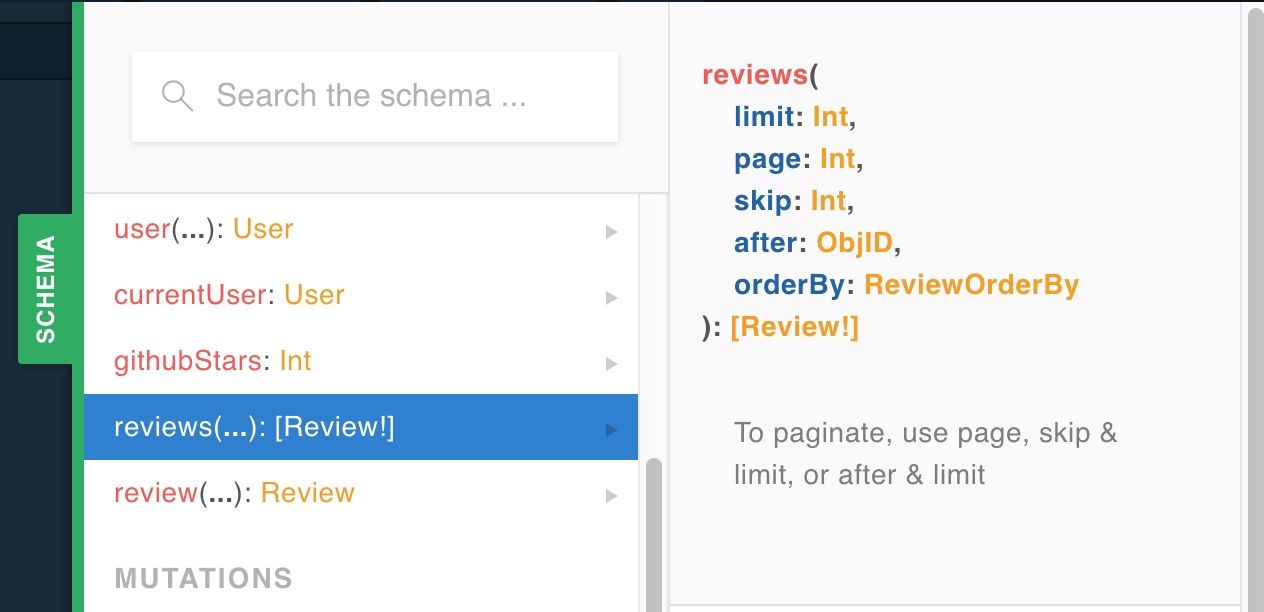
Let’s see this in action. Normally an API will support a single pagination method, but, as we can see from this schema comment, the reviews query supports three different methods:
page
If you’re jumping in here,
git checkout 16_1.0.0(tag16_1.0.0). Tag17_1.0.0contains all the code written in this section.
Let’s try page first. We switch our ReviewQuery from using the limit parameter to using the page parameter, and we use a variable so that <Reviews> can say which page it wants.
src/graphql/Review.js
export const REVIEWS_QUERY = gql`
query ReviewsQuery($page: Int) {
reviews(page: $page) {
...ReviewEntry
}
}
${REVIEW_ENTRY}
`src/components/Reviews.js
const { data: { reviews } = {}, loading } = useQuery(REVIEWS_QUERY, {
variables: { page: 1 },
errorPolicy: 'all',
})Now the page displays the first 10 reviews. If we change it to { page: 2 }, we see the second 10 reviews. We could make the page number dynamic, but let’s instead make the next method dynamic: skip and limit.
skip and limit
To use the skip and limit parameters, we replace page with them in the query:
export const REVIEWS_QUERY = gql`
query ReviewsQuery($skip: Int, $limit: Int) {
reviews(skip: $skip, limit: $limit) {
...ReviewEntry
}
}
${REVIEW_ENTRY}
`and update our component:
const { data: { reviews } = {}, loading } = useQuery(REVIEWS_QUERY, {
variables: { skip: 0, limit: 10 },
errorPolicy: 'all',
})We still see the first 10 reviews, as expected. To make sure it works, we can view the next 10 by editing it to be { skip: 10, limit: 10 }.
Let’s implement infinite scroll, during which the component will provide new values for skip when the user scrolls to the bottom of the page. First, let’s simplify what we’re working with by extracting out the list of reviews to <ReviewList>. <Reviews> will be left with the header and the add button:
import ReviewList from './ReviewList'
...
export default () => {
...
return (
<main className="Reviews mui-fixed">
<div className="Reviews-header-wrapper">
...
</div>
<ReviewList />
{user && (
<div>
<Fab
onClick={() => setAddingReview(true)}
color="primary"
className="Reviews-add"
>
<Add />
</Fab>
<Modal open={addingReview} onClose={() => setAddingReview(false)}>
<ReviewForm done={() => setAddingReview(false)} />
</Modal>
</div>
)}
</main>
)
}Here’s our new <ReviewList>:
import React from 'react'
import { useQuery } from '@apollo/client'
import Review from './Review'
import { REVIEWS_QUERY } from '../graphql/Review'
export default () => {
const { data: { reviews } = {}, loading } = useQuery(REVIEWS_QUERY, {
variables: { skip: 0, limit: 10 },
errorPolicy: 'all',
})
return (
<div className="Reviews-content">
{loading ? (
<div className="Spinner" />
) : (
reviews.map((review) => <Review key={review.id} review={review} />)
)}
</div>
)
}We’re going to want a spinner at the bottom of the list of reviews to indicate that we’re loading more. When the list is really long—as it is in the case of reviews—we don’t need to code hiding the spinner, since it’s unlikely users will reach the end 😄. Since we’ll always have a spinner, we no longer need loading:
export default () => {
const { data } = useQuery(REVIEWS_QUERY, {
variables: { skip: 0, limit: 10 },
errorPolicy: 'all',
})
const reviews = (data && data.reviews) || []
return (
<div className="Reviews-content">
{reviews.map((review) => (
<Review key={review.id} review={review} />
))}
<div className="Spinner" />
</div>
)
}Note that reviews is undefined during loading, so in order to prevent reviews.map from throwing an error, we need a default value of [] for reviews.
useQuery() returns a fetchMore property that we can use to fetch more data using the same query but different variables—in our case, the next set of reviews.
Let’s call fetchMore() when the user approaches the bottom of the page:
import { useEffect } from 'react'
export default () => {
const { data, fetchMore } = useQuery(REVIEWS_QUERY, {
variables: { skip: 0, limit: 10 },
errorPolicy: 'all',
})
const reviews = (data && data.reviews) || []
const onScroll = () => {
const currentScrollHeight = window.scrollY + window.innerHeight
const pixelsFromBottom =
document.documentElement.scrollHeight - currentScrollHeight
const closeToBottom = window.scrollY > 0 && pixelsFromBottom < 250
if (closeToBottom) {
// TODO call fetchMore
}
}
useEffect(() => {
window.addEventListener('scroll', onScroll)
return () => window.removeEventListener('scroll', onScroll)
}, [onScroll])
return ...
}We register a scroll listener inside of useEffect(). The listener checks the current scroll position, and if we’re less than 250 pixels from the bottom, will call fetchMore(), which we’ll implement next:
if (closeToBottom) {
fetchMore({ variables: { skip: reviews.length } })
}We can keep the same limit by not including it in variables. And we know how many to skip for the next query—the amount we currently have, data.reviews.length.
If we test this out, nothing happens! If we check the cache, we see that another entry was added to ROOT_QUERY:
> __APOLLO_CLIENT__.cache.data.data.ROOT_QUERY
...
reviews({"limit":10,"skip":0}): (10) [{…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}]
reviews({"limit":10,"skip":10}): (10) [{…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}]The second entry, with "skip":10 was added after we scrolled to the bottom of the page. But our <ReviewsList /> component still just displays the first list. The solution is to merge the second list into the first list when it arrives from the server. We do this with a cache merge function. There’s a built-in merge function called concatPagination that just concats the incoming list onto the end of the existing list, so let’s try that:
import { concatPagination } from '@apollo/client/utilities'
const cache = new InMemoryCache({
typePolicies: {
Query: {
fields: {
reviews: concatPagination(),
},
},
},
})
export const apollo = new ApolloClient({ link, cache })Now when we re-test, it works! One issue is that scroll events fire often, so once the user passes the threshold, we’re calling fetchMore() a lot 😜. We only need to once, so we want to stop ourselves from calling it again if we just called it. We can tell whether we just called it by looking at networkStatus, a property returned by useQuery(), which has a numerical value corresponding with different statuses—loading, ready, polling, refetching, etc. It’s 3 while Apollo is fetching more data, and then goes back to 7 (ready) when the data has arrived. Here are all the possible values:
1: "loading"
2: "setVariables"
3: "fetchMore"
4: "refetch"
6: "poll"
7: "ready"
8: "error"They’re also exported in the NetworkStatus enum. Let’s skip fetchMore() if the current status is NetworkStatus.fetchMore:
import { NetworkStatus } from '@apollo/client'
import throttle from 'lodash/throttle'
export default () => {
const { data, fetchMore, networkStatus } = useQuery(REVIEWS_QUERY, {
variables: { skip: 0, limit: 10 },
errorPolicy: 'all',
notifyOnNetworkStatusChange: true,
})
const reviews = (data && data.reviews) || []
const onScroll = throttle(() => {
if (networkStatus !== NetworkStatus.fetchMore) {
const currentScrollHeight = window.scrollY + window.innerHeight
const pixelsFromBottom =
document.documentElement.scrollHeight - currentScrollHeight
const closeToBottom = window.scrollY > 0 && pixelsFromBottom < 250
if (closeToBottom && reviews.length > 0) {
fetchMore({ ... })
}
}
}, 100)
useEffect(() => {
window.addEventListener('scroll', onScroll)
return () => window.removeEventListener('scroll', onScroll)
}, [onScroll])
return ...
}In addition to the if (networkStatus !== NetworkStatus.fetchMore) check, we also added:
notifyOnNetworkStatusChange: trueoption touseQuery()so that thenetworkStatusproperty gets updated.throttle(() => ..., 100)toonScrollso that the function isn’t run more than once every 100 milliseconds.if (closeToBottom && reviews.length > 0)in case the response to the initial reviews query hasn’t yet arrived.
Another issue we’ve got is what happens when someone else adds a review during the time between when the user loads the page and when they scroll to the bottom. loadMoreReviews() will query for reviews(skip: 10, limit: 10), which will return items 11-20. However, the 11th item now is the same as the 10th item before, and we already have the 10th item in the cache. When they’re combined with concatPagination(), the reviews list has a duplicated item. And since we use the review’s id for the key, React gives us this error in the console:
Warning: Encountered two children with the same keyWe can prevent duplicate objects from being saved in the cache by writing a custom merge function:
import find from 'lodash/find'
const cache = new InMemoryCache({
typePolicies: {
Query: {
fields: {
reviews: {
merge(existing = [], incoming, { readField }) {
const notAlreadyInCache = (review) =>
!find(
existing,
(existingReview) =>
readField('id', existingReview) === readField('id', review)
)
const newReviews = incoming.filter(notAlreadyInCache)
return [...existing, ...newReviews]
},
keyArgs: false,
},
},
},
},
})The merge function gets three arguments:
existing: The result currently in the cache.incoming: The result being written to the cache (usually it just arrived from the server).- An object with helper functions.
First, we filter out all of the reviews that are already in the cache (see note at the end of the Client-side ordering & filtering section for how to make this more efficient). Then we concatenate the existing reviews with the new reviews. Since Review objects are normalized in the cache, existing and incoming are arrays of references to Reviews. This means we can’t do review.id—instead, we use the readField helper function: readField('id', review).
keyArgs defines which arguments result in a different entry in the cache. It defaults to all the arguments, which in this case would be keyArgs: ['skip', 'limit']. We do not want a different entry in the cache created when we change our pagination arguments, so we do keyArgs: false.
We can test it out by setting a skip that’s too low, for instance:
variables: { skip: reviews.length - 5 },Now when we scroll down, we should have 15 total reviews on the page instead of 20, and we no longer get the React duplicate key error.
It seems strange at first, but subtracting some number from the length is a good idea to leave in the code! It makes sure—in the case in which some of the first 10 items are deleted—that we don’t miss any items. If we still want 10 new items to (usually) show up when we scroll down, then we can also change limit to 15:
variables: { skip: reviews.length - 5, limit: 15 },While our pagination now works, creating and deleting reviews has stopped working! When we try, we get an error:
MissingFieldError
message: "Can't find field 'reviews' on ROOT_QUERY object"
path: ["reviews"]
query: {kind: "Document", definitions: Array(2), loc: Location}
variables: {}In our add and remove update functions, we’re trying to read REVIEWS_QUERY from the cache. Since we’re not specifying variables there, it looks in the cache for the root query field reviews({}), with no arguments. And we don’t have that in our cache, because we’ve never done a REVIEWS_QUERY without arguments—we’ve only done it with a skip and limit. We can enter the below into the browser console to print out the current Apollo cache’s state:
> __APOLLO_CLIENT__.cache.data.data.ROOT_QUERY
{
chapters: (14) [{…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}]
currentUser: {__ref: "User:5a4ca4eb10bda60096ea8f01"}
githubStars: 103
reviews({"limit":10,"skip":0}): (10) [{…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}]
__typename: "Query"
}We can see that our reviews query has both arguments:
reviews({"limit":10,"skip":0}): ...We could try to fix this by providing the same arguments to cache.readQuery, so that Apollo knows which field on ROOT_QUERY to read from:
src/graphql/Review.js
export const REVIEWS_QUERY = ...
export const REVIEWS_QUERY_FROM_CACHE = {
query: REVIEWS_QUERY,
variables: {
skip: 0,
limit: 10,
},
}src/components/ReviewForm.js
import { REVIEW_ENTRY, REVIEWS_QUERY_FROM_CACHE } from '../graphql/Review'
const [addReview] = useMutation(ADD_REVIEW_MUTATION, {
update: (store, { data: { createReview: newReview } }) => {
const { reviews } = store.readQuery(REVIEWS_QUERY_FROM_CACHE)
store.writeQuery({
...REVIEWS_QUERY_FROM_CACHE,
data: { reviews: [newReview, ...reviews] },
})
},
})src/components/Review.js
import { REVIEWS_QUERY_FROM_CACHE } from '../graphql/Review'
const [removeReview] = useMutation(REMOVE_REVIEW_MUTATION, {
update: (cache) => {
const { reviews } = cache.readQuery(REVIEWS_QUERY_FROM_CACHE)
cache.writeQuery({
...REVIEWS_QUERY_FROM_CACHE,
data: { reviews: reviews.filter((review) => review.id !== id) },
})However, the problem with this approach is that doing writeQuery() runs the data through our InMemoryCache typePolicies—in particular, our reviews merge function. In the case of adding a review, our merge puts the new review at the end of the list, not the beginning, and in the case of removing a review, does nothing: the merge function gets the list of all-but-one reviews, filters them through notAlreadyInCache (resulting in newReviews = []), and returns [...existing, ...newReviews]:
import find from 'lodash/find'
const cache = new InMemoryCache({
typePolicies: {
Query: {
fields: {
reviews: {
merge(existing = [], incoming, { readField }) {
const notAlreadyInCache = (review) =>
!find(
existing,
(existingReview) =>
readField('id', existingReview) === readField('id', review)
)
const newReviews = incoming.filter(notAlreadyInCache)
return [...existing, ...newReviews]
},
keyArgs: false,
},
},
},
},
})The solution is to use cache.modify() instead of cache.writeQuery(). cache.modify() directly modifies the data in the cache, bypassing all typePolicies. Let’s fix addReview’s update function:
export default ({ done, review }) => {
...
const [addReview] = useMutation(ADD_REVIEW_MUTATION, {
update: (cache, { data: { createReview: newReview } }) => {
cache.modify({
fields: {
reviews(existingReviewRefs = []) {
const newReviewRef = cache.writeFragment({
data: newReview,
fragment: gql`
fragment NewReview on Review {
id
text
stars
createdAt
favorited
author {
id
}
}
`,
})
return [newReviewRef, ...existingReviewRefs]
},
},
})
},
})cache.modify() takes a fields object, and we provide a reviews() function to modify the reviews root query field in the cache (__APOLLO_CLIENT__.cache.data.data.ROOT_QUERY.reviews). reviews() receives as an argument the current cache contents, which is a list of reviews. But unlike .readQuery(), it’s an array of references to the normalized Review cache objects rather than the objects themselves. And instead of adding an object to the beginning of the array, we write a new Review object to the cache and put a reference to it in the array.
Next we’ll fix removeReview’s update function:
const [removeReview] = useMutation(REMOVE_REVIEW_MUTATION, {
update: (cache) => {
cache.modify({
fields: {
reviews: (reviewRefs, { readField }) =>
reviewRefs.filter((reviewRef) => readField('id', reviewRef) !== id),
}
})
}
})As we did with our merge function, we use readField to read review object properties from the cache. And to help ourselves remember that we’re dealing with references to normalized objects in the cache instead of the review objects themselves, we name the variables reviewRefs and reviewRef.
Now our new reviews are successfully written to the cache. However, we might notice that when we delete a favorited review, the favorite count in the header doesn’t update. We need to update the currentUser.favoriteReviews field in our cache. To update a nested field, we can make another call to cache.modify() inside the fields.currentUser function:
const [removeReview] = useMutation(REMOVE_REVIEW_MUTATION, {
update: (cache) => {
cache.modify({
fields: {
reviews: (reviewRefs, { readField }) =>
reviewRefs.filter((reviewRef) => readField('id', reviewRef) !== id),
currentUser(currentUserRef) {
cache.modify({
id: currentUserRef.__ref,
fields: {
favoriteReviews: (reviewRefs, { readField }) =>
reviewRefs.filter(
(reviewRef) => readField('id', reviewRef) !== id
),
},
})
return currentUserRef
},
},
})
},
})In the case of our first call to cache.modify(), we didn’t need an id because we’re editing root query fields. But for the second call, currentUser is a normalized User object, and to modify a normalized object, we need to provide its id.
This works, but it’s a lot of code to remove a single object. (And it doesn’t actually even remove the object from the cache. It’s still there, we just removed two references to it.) Fortunately, there’s another cache method we can use to simplify: cache.evict(). Given the cache ID of an object, it removes the object from the cache:
const [removeReview] = useMutation(REMOVE_REVIEW_MUTATION, {
update: (cache) => cache.evict({ id: cache.identify(review) }),
})We use the cache.identify() method to get the cache ID of review. It works on any object that has both a __typename and an id.
An issue with
cache.evict()is that when the mutation response has an error, the optimistic eviction isn’t rolled back. In the future, we’ll be able to fix this withcache.evict({ id: ..., optimistic: true }).
Our cache.evict() appears to work just as well as our cache.modify() code. What happened to the references, we might wonder? They’re still there. They’re called dangling references, because the object they refer to no longer exists. They’re not a problem for us because by default, Apollo filters them out of array fields.
We may recall this favoriteReviews filtering from our FAVORITE_REVIEW_MUTATION update function, where we used readQuery() and writeQuery(). We can shorten that code by using a nested cache.modify():
const [favorite] = useMutation(FAVORITE_REVIEW_MUTATION, {
update: (cache, { data: { favoriteReview } }) => {
cache.modify({
fields: {
currentUser(currentUserRef) {
cache.modify({
id: currentUserRef.__ref,
fields: {
favoriteReviews: (reviewRefs, { readField }) =>
favoriteReview.favorited
? [...reviewRefs, { __ref: `Review:${id}` }]
: reviewRefs.filter(
(reviewRef) => readField('id', reviewRef) !== id
),
},
})
return currentUserRef
},
},
})
},
})If the review was just favorited, we add a reference to it to the favoriteReviews list. Otherwise, we filter it out. The format of a cache reference is { __ref: 'cache-ID' }. If we had a review cache object like { __typename: 'Review', id: '5a4ca4eb10bda60096ea8f01' }, then we could do { __ref: cache.identify(review) }, but since all we have here is the id prop, we construct the cache ID manually: { __ref: Review:${id} }.
Back in our reviews query, what happens when fetchMore() changes skip to 10 or 20? Do we need to also update our calls to cache.modify() or readQuery()? It turns out that we don’t need to: since we set keyArgs: false in the reviews field policy, when we call fetchMore(), the additional results get added to the cache under the original root query field. We can see this is the case by scrolling down, opening Apollo devtools -> Cache, and looking at ROOT_QUERY:
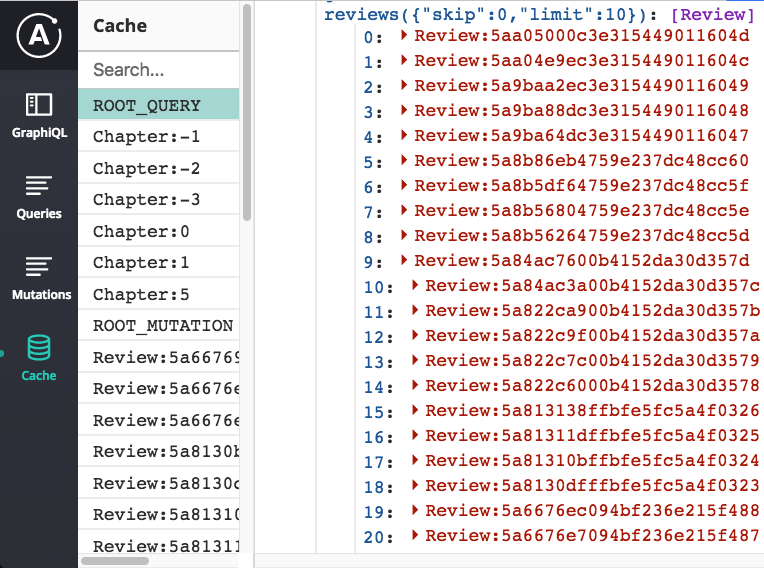
Or by entering __APOLLO_CLIENT__.cache.data.data.ROOT_QUERY in the console.
Cursors
If you’re jumping in here,
git checkout 17_1.0.0(tag17_1.0.0). Tag18_1.0.0contains all the code written in this section.
Subsections:
Cursor-based pagination uses a cursor—a pointer to where we are in a list. With cursors, the schema looks different from the Guide schema we’ve been working with. Our queries could look something like:
{
listReviews (cursor: $cursor, limit: $limit) {
cursor
reviews {
...ReviewEntry
}
}
}Each query comes back with a cursor, which we then include as an argument in our next query. A cursor usually encodes both the ID of the last item and the list’s sort order, so that the server knows what to return next. For instance, if the first 10 reviews ended with a review that had an ID of 100, and the list was ordered by most recently created, the cursor could be 100:createdAt_DESC, and the query could be:
{
listReviews (cursor: "100:createdAt_DESC", limit: 10) {
cursor
reviews {
...ReviewEntry
}
}
}It would return:
{
"data": {
"listReviews": {
"cursor": "90:createdAt_DESC",
"reviews": [{
"id": "99"
...
},
...
{
"id": "90"
...
}]
}
}
}And then our next query would be listReviews (cursor: "90:createdAt_DESC", limit: 10).
This is a simple version of cursors. If we’re working with a server that follows the Relay Cursor Connections spec (with edges and nodes and pageInfos), we can follow this example for querying it.
after
Let’s implement a version of pagination that has the same information—last ID and sort order—but works within the Guide schema. We can see in Playground that there are a couple of arguments we haven’t used yet—after and orderBy:
enum ReviewOrderBy {
createdAt_ASC
createdAt_DESC
}
# To paginate, use page, skip & limit, or after & limit
reviews(limit: Int, page: Int, skip: Int, after: ObjID, orderBy: ReviewOrderBy): [Review!]First, let’s use the last review’s ID for after, and remove skip:
export default () => {
const { data, fetchMore, networkStatus } = useQuery(REVIEWS_QUERY, {
variables: { limit: 10 },
...
}
...
if (closeToBottom && reviews.length > 0) {
const lastId = reviews[reviews.length - 1].id
fetchMore({ variables: { after: lastId } })We also have to update the query:
query ReviewsQuery($after: ObjID, $limit: Int) {
reviews(after: $after, limit: $limit) {It works! And it’s so precise that we don’t have to worry about things getting added or deleted between fetchMores. We could even switch our merge field policy back to concatPagination. One might be concerned about the possibility of the review we’re using as a cursor being deleted, but some server implementations cover this case—the Guide API is backed by MongoDB, which has IDs that are comparable based on order of creation, so the server can still find IDs that were created before or after the deleted ID.
orderBy
Next let’s figure out how to get sort order working as well. The two possible values are createdAt_DESC (newest reviews first, the default) and createdAt_ASC. If we put a “Newest/Oldest” select box in <Reviews>, then we can pass the value down to <ReviewList> to use in the query’s variables:
import { MenuItem, FormControl, Select } from '@material-ui/core'
export default () => {
const [orderBy, setOrderBy] = useState('createdAt_DESC')
...
return (
<main className="Reviews mui-fixed">
<div className="Reviews-header-wrapper">
<header className="Reviews-header">
...
<FormControl>
<Select
value={orderBy}
onChange={(e) => setOrderBy(e.target.value)}
displayEmpty
>
<MenuItem value="createdAt_DESC">Newest</MenuItem>
<MenuItem value="createdAt_ASC">Oldest</MenuItem>
</Select>
</FormControl>
</header>
</div>
<ReviewList orderBy={orderBy} />In <ReviewList>, we need to use the new prop in the query:
export default ({ orderBy }) => {
const { data, fetchMore, networkStatus } = useQuery(REVIEWS_QUERY, {
variables: { limit: 10, orderBy },
...
fetchMore({ variables: { after: lastId, orderBy } })Testing it out, we find that nothing happens when we change the select input to “Oldest.” We can also see in the Network tab that no GraphQL request is sent. Since the Query.reviews field policy keyArgs is false, there is only a single entry in the cache for all sets of variables. And since this query is using the default cache-first fetch policy, Apollo looks in the cache for results that match, finds the existing entry (which was created when the “Newest” query was made on pageload), and returns it.
To fix this, we want separate entries in the cache for orderBy: createdAt_DESC and orderBy: createdAt_ASC. We tell Apollo to do this by changing keyArgs: false:
const cache = new InMemoryCache({
typePolicies: {
Query: {
fields: {
reviews: {
merge ...
keyArgs: ['orderBy'],
},The select input now works—when we change it to “Oldest”, the query variable updates, and a different list of reviews loads. When we go back to “Newest”, the original list immediately appears, because Apollo has that list cached under the original orderBy. We can see in devtools that both lists are indeed cached:
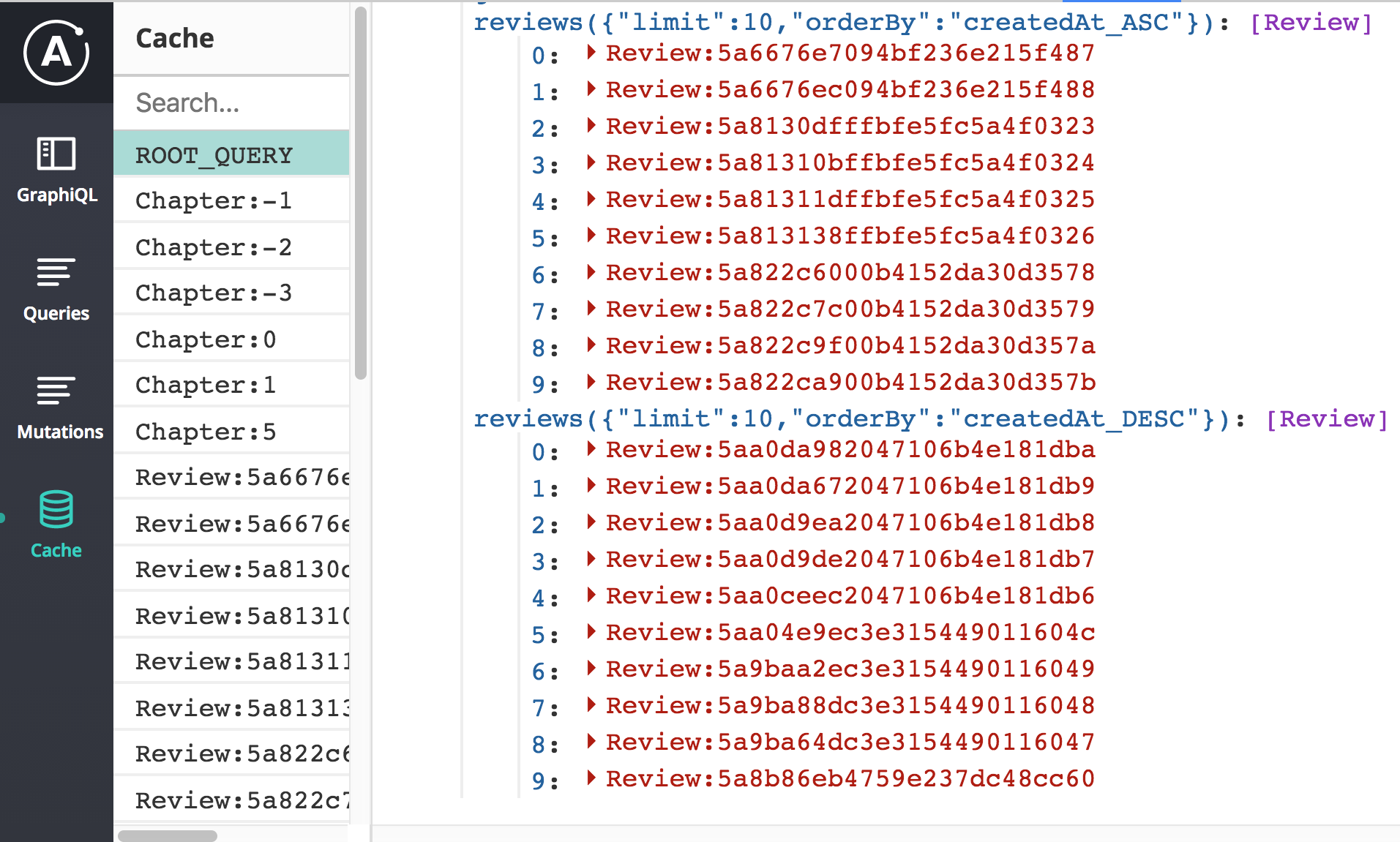
However, we have another bug! Can you find it? 🔍🐞
When we switch to “Oldest” and create a new review, it appears at the top of the list as if it were the oldest review. But it’s the newest. Our ADD_REVIEW_MUTATION cache.modify() puts the new review at the beginning of the list. And when we have multiple reviews entries in our cache (since we changed keyArgs), our cache.modify() field functions are called once for each cache entry. So the new review is added to the top of both the createdAt_DESC entry and the createdAt_ASC entry. Let’s only add it to createdAt_DESC by checking the storeFieldName, which has the argument in it (for example, reviews:{"orderBy":"createdAt_DESC"} is the field name for the “Oldest” entry):
const [addReview] = useMutation(ADD_REVIEW_MUTATION, {
update: (cache, { data: { createReview: newReview } }) => {
cache.modify({
fields: {
reviews(existingReviewRefs = [], { storeFieldName }) {
if (!storeFieldName.includes('createdAt_DESC')) {
return existingReviewRefs
}
const newReviewRef = cache.writeFragment({
data: newReview,
fragment: gql`
fragment NewReview on Review {
id
text
stars
createdAt
favorited
author {
id
}
}
`,
})
return [newReviewRef, ...existingReviewRefs]
},
},
})
},
})Fixed!
The other mutation we have that modifies the reviews list is REMOVE_REVIEW_MUTATION. In that case, it’s helpful that our cache.modify() reviews function gets run on all Query.reviews cache entries. This means that if the deleted review is in both lists, it will be deleted from both.