Federated service
To view this content, get the Pro package! 😃🙏
Or if you’ve already purchased.
Federated service
If you’re jumping in here,
git checkout federation_0.1.0(tag federation_0.1.0, or compare federation...federation2)
In this section we’ll build a users service: A GraphQL server that supports Apollo federation and handles queries related to the User type. We’ll start from a new tag:
$ git clone https://github.com/GraphQLGuide/guide-api.git
$ cd guide-api/
$ git checkout federation_0.1.0
$ npm installHere is our starting file structure:
$ tree -L 3
.
├── babel.config.json
├── lerna.json
├── lib
│ ├── Date.js
│ ├── auth.js
│ ├── db.js
│ └── errors.js
├── package.json
└── services
├── reviews
│ └── package.json
└── users
└── package.jsonThe two services will go in the services/ folder, and lib/ contains code to share between the services (taken from the monolith we built earlier). Let’s install all the modules we need:
$ npm installThis creates a node_modules/ at the root—which has modules for the gateway code that we’ll place at the root—and it also creates node_modules/ folders inside services/reviews/ and services/users/ thanks to the Lerna library, which we configure in lerna.json and use in a postinstall script in package.json:
{
"name": "guide-api",
"version": "0.1.0",
"scripts": {
"start": "babel-watch gateway.js",
"start-service-users": "babel-watch services/users/index.js",
"start-service-reviews": "babel-watch services/reviews/index.js",
"start-services": "concurrently \"npm:start-service-*\"",
"postinstall": "lerna bootstrap"
},
...
}We also see from the scripts where we’ll locate the main server files:
gateway.js
services/users/index.js
services/reviews/index.jsconcurrently runs multiple other scripts in the same terminal—in this case, both start-service-users and start-service-reviews.
In this section, we’ll be filling in services/users/*. There are three main parts to a federated service:
buildFederatedSchema(): Instead of passingtypeDefsandresolversdirectly toApolloServer(), we give them to thebuildFederatedSchema()from the@apollo/federationlibrary.- Entities: Types defined in one service that can be referenced or extended by other services.
@keydirective: Each entity requires a@keydirective denoting the primary key.__resolveReference(): For each entity, we must write a reference resolver, which fetches an entity object by its@keyfield(s).
As usual, let’s start with the schema:
import { gql } from 'apollo-server'
export default gql`
scalar Date
extend type Query {
me: User
user(id: ID!): User
}
type User @key(fields: "id") {
id: ID!
firstName: String!
lastName: String!
username: String!
email: String
photo: String!
createdAt: Date!
updatedAt: Date!
}
`We include shared types like custom scalars in the schema of each service. Also, the Query and Mutation types will be initially defined in the gateway, so the services extend them. Finally, our User type has this directive: @key(fields: "id"), which tells the gateway that the User type is a federation entity and the id field is its primary key.
We copy the below from our monolith’s src/resolvers/User.js with a couple of additions:
- Adding the
Dateresolvers, imported fromlib/Date.js - Adding
User.__resolveReference
import { ForbiddenError } from 'apollo-server'
import { ObjectId } from 'mongodb'
import { InputError } from '../../lib/errors'
import Date from '../../lib/Date'
const OBJECT_ID_ERROR =
'Argument passed in must be a single String of 12 bytes or a string of 24 hex characters'
export default {
...Date,
Query: {
me: (_, __, context) => context.user,
user: (_, { id }, { dataSources }) => {
try {
return dataSources.users.findOneById(ObjectId(id))
} catch (error) {
if (error.message === OBJECT_ID_ERROR) {
throw new InputError({ id: 'not a valid Mongo ObjectId' })
} else {
throw error
}
}
}
},
User: {
__resolveReference: (reference, { dataSources }) =>
dataSources.users.findOneById(ObjectId(reference.id)),
id: ({ _id }) => _id,
email(user, _, { user: currentUser }) {
if (!currentUser || !user._id.equals(currentUser._id)) {
throw new ForbiddenError(`cannot access others' emails`)
}
return user.email
},
photo(user) {
// user.authId: 'github|1615'
const githubId = user.authId.split('|')[1]
return `https://avatars.githubusercontent.com/u/${githubId}`
},
createdAt: user => user._id.getTimestamp()
}
}The first argument to __resolveReference is the reference: An object containing the primary key field(s)—in this case, just the id—which we resolve to the user object.
Now we put the resolvers and schema together to create the server:
import { ApolloServer } from 'apollo-server'
import { buildFederatedSchema } from '@apollo/federation'
import { MongoDataSource } from 'apollo-datasource-mongodb'
import resolvers from './resolvers'
import typeDefs from './schema'
import { mongoClient } from '../../lib/db'
import context from '../../lib/userContext'
const server = new ApolloServer({
schema: buildFederatedSchema([
{
typeDefs,
resolvers
}
]),
dataSources: () => ({
users: new MongoDataSource(mongoClient.db().collection('users'))
}),
context
})
mongoClient.connect()
server.listen({ port: 4001 }).then(({ url }) => {
console.log(`Users service ready at ${url}`)
})Here we see the use of buildFederatedSchema(). Also, the only data source method we use is .findOneById(), so we can use MongoDataSource directly instead of defining a subclass. mongoClient we get from db.js:
import { MongoClient } from 'mongodb'
const URL = 'mongodb://localhost:27017/guide'
export const mongoClient = new MongoClient(URL)Finally, our context function needs to provide a user object for the Query.me resolver. Our monolith context function looked at the authorization header, decoded the authId, and fetched the user object. Instead of having each of our services repeat this process, we can have our gateway do part or all of it. We can either do:
- Gateway decodes
authIdand passes it to services as anauth-idheader. Services read the header and fetch the user document. - Gateway decodes
authId, connects to the user database to fetch the user document, and passes it to services as auserheader. - The JWT that’s sent in the authorization header from the client can be created to contain the whole user document, so that when it’s decoded, no database query is required.
Our JWTs don’t have the whole user document, so we can’t do #3. Between #1 and #2, #2 is more efficient, as it reduces the number of database calls. Note that #2 isn’t possible when the user document is large. The maximum header size is set by the receiving server, for instance Nginx has a maximum 4KB, which is ~4,000 ASCII characters. (We can check the length of a user document by doing JSON.stringify(user).length.) Here is the service side of #2:
module.exports = async ({ req }) => {
const context = {}
const userDocString = req && req.headers['user']
if (userDocString) {
context.user = JSON.parse(userDocString)
}
return context
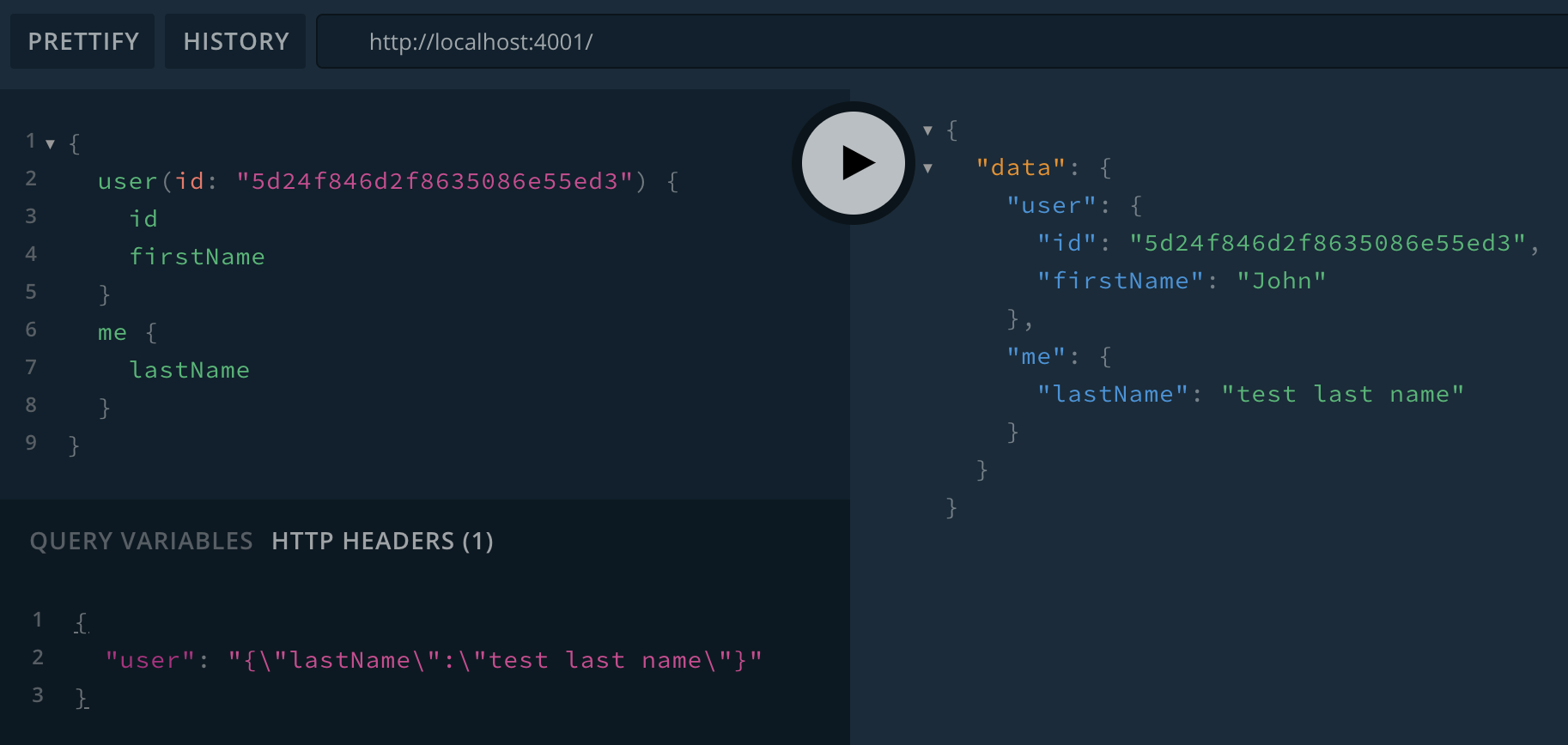
}Now we can set the user HTTP header and both Query.user and Query.me work:
$ npm run start-service-users
> [email protected] start-service-users /guide-api
> babel-watch services/users/index.js
Users service ready at http://localhost:4001/