Client libraries
To view this content, buy the book! 😃🙏
Or if you’ve already purchased.
Client libraries
There are many different GraphQL client libraries for different platforms and languages. Here is some common functionality that the libraries might provide:
The first is useful anywhere—whether it’s a script, service, or website that’s mostly static (only displays a small amount of dynamically fetched data). The second is useful when we’re working in a typed programming language. The last three are extremely helpful for building applications: whether we’re making a web app, a mobile app, or a desktop app, we usually need to fetch and display a number of different types of data from the server, and decide which to fetch and display based on user interactions. We also want to remember what we requested in the past, because often when we need to display it again, we don’t need to fetch it again. Doing all of this ourselves can get really complicated, but advanced client libraries like Apollo can take care of a lot of it for us.
Streamlined request function
The most basic thing a library does is give us something like the
makeGraphqlRequest() function we wrote above, which takes care
of constructing the HTTP POST request and parsing the response. For instance, the graphql-request client library does this (and only this).
Typing
When we’re working in typed languages, we have to write our own object types and models, and when we get JSON from a REST API, we have to convert the data into our types. With GraphQL, we know the types for everything because they’re in the schema. Which means that our client libraries can provide us with type definitions or generate typed model code for us. For instance, apollo-codegen generates type definitions for Typescript, Flow, and Scala, Apollo iOS returns query-specific Swift types, and Apollo-Android generates typed Java models based on our queries and schema.
A combination of having a schema and query documents also allow for some great code editor features, such as autocomplete, go to definition, and schema validation. (See, for example, the VS Code plugin and IntelliJ/WebStorm plugin.)
View layer integration
Most libraries even take care of calling makeGraphqlRequest for us: we simply add
our query documents to the components that need them, and when those components
are rendered, the documents get combined into a request to the server. When we
get data back from a GraphQL server, we usually want to display it to the user—and depending on the view layer, our library may have handy ways of helping us
do that, as well as handling loading state and errors. We’ll see some specific examples of this in the React, React Native, and Vue sections.
Caching
Background: latency
All of the libraries we’ll use cache the data we get from the GraphQL server—that is, they store the data, either in memory or on disk, so that we can immediately access it later without having to request it again from the server. While some libraries just cache the whole response and give us the cached response when we make the exact same request, the most useful libraries store the data in a normalized cache. A normalized cache breaks down the response and saves each object separately, so that if we make a different, overlapping query, the library can still give us the cached data. As an example, let’s consider this part of the schema of the Guide:
type Query {
currentUser: User
section(id: Int!): Section
}
type User {
firstName: String
hasRead: [Section]
}
type Section {
title: String!
}When a user visits their profile, we want to show a list of which sections they’ve read, so we send this query:
{
currentUser {
id
firstName
hasRead {
id
title
}
}
}Our query returns:
{
"currentUser": {
"id": "1",
"firstName": "Loren",
"hasRead": [
{
"id": "5_1",
"title": "Anywhere: HTTP"
},
{
"id": "5_2",
"title": "Client Libraries"
}
]
}
}And our library saves the response in a normalized cache. The key to each object
in the cache is a string of the format "[type]:[object id]", for instance
"User:1" for a User object with an id of 1:
cache = {
"User:1": {
id: "1",
firstName: "Loren",
hasRead: [
"Section:5_1",
"Section:5_2"
]
},
"Section:5_1": {
id: "5_1",
title: "Anywhere: HTTP"
},
"Section:5_2": {
id: "5_2",
title: "Client Libraries"
}
}If the user then navigates to section 5_2, we want to display the title of
that section, so we look it up with this query:
{
section(id: "5_2") {
title
}
}Which should return:
{
"section": {
"title": "Client Libraries"
}
}But we already know from our first query that "Client Libraries" is the title.
Our normalized caching library, instead of sending our second query to the
server, can find the object with the "Section:5_2" key in the cache and
immediately return it to us.
Sometimes we want to re-request data from the server, because it may have changed since we originally requested it. Client libraries certainly allow us to re-request, but we usually want to immediately display the cached data while we wait for the response to arrive. The time it takes to get a value from the cache and display it on the screen could be as little as 20ms, whereas common response times from GraphQL servers are on the order of hundreds of milliseconds or seconds, depending on the user’s network connection latency and how long the server takes to retrieve their data. Humans perceive delays above 100ms, so UX best practice is to show something on the screen within 100ms of a user action. We probably won’t get a response from our GraphQL server in time, so we’ll want to either communicate that we’re waiting—for example by displaying a spinner—or display the cached version of the data.
DevTools
Some libraries have browser DevTools extensions for viewing information about an app’s GraphQL operations and the current state of the cache. Apollo’s DevTools also has a built-in GraphiQL that uses the same network link as our app, so we don’t have to manually set authentication headers. We can even use it to query the cache instead of the server by checking “Load from cache”:
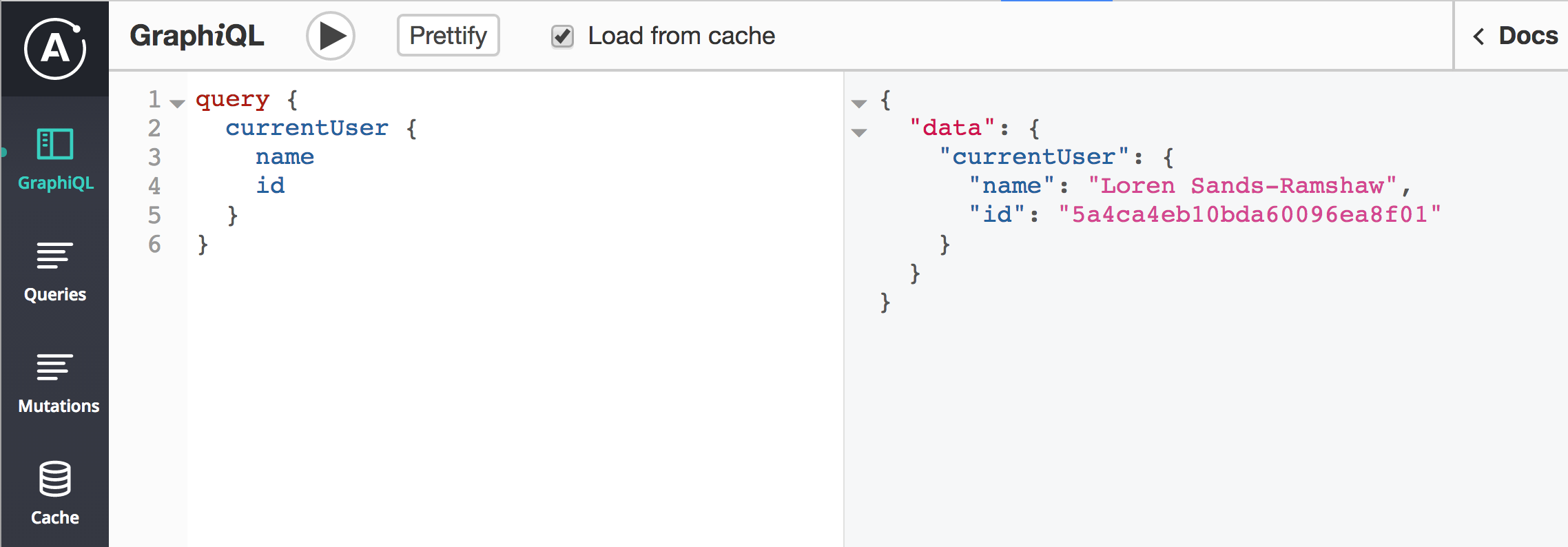
Under the Queries tab, we see the current “Watched queries” (queries attached to our components) and what variables they were called with:
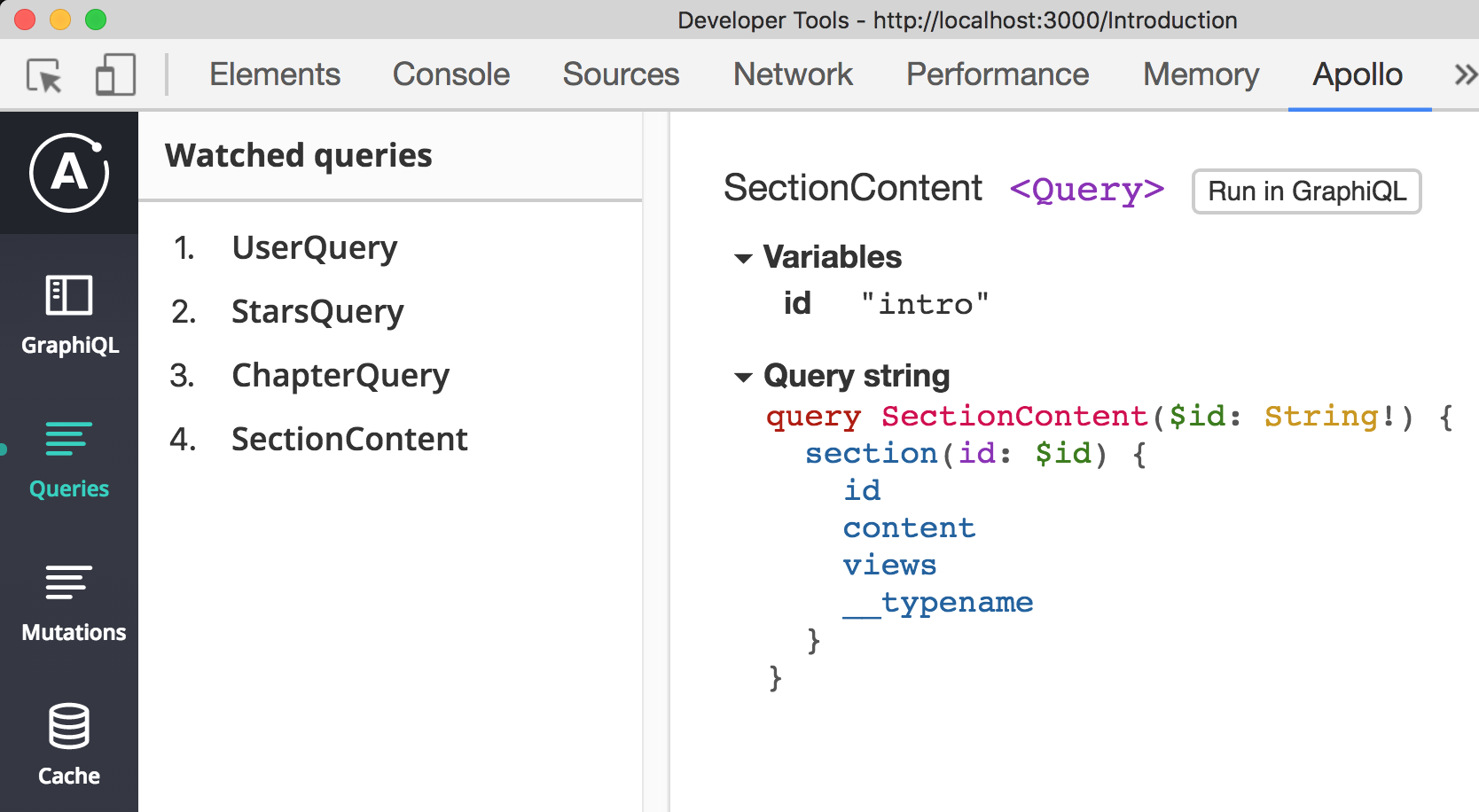
Under the Mutations tab, we see a log of all past mutations and their variables:
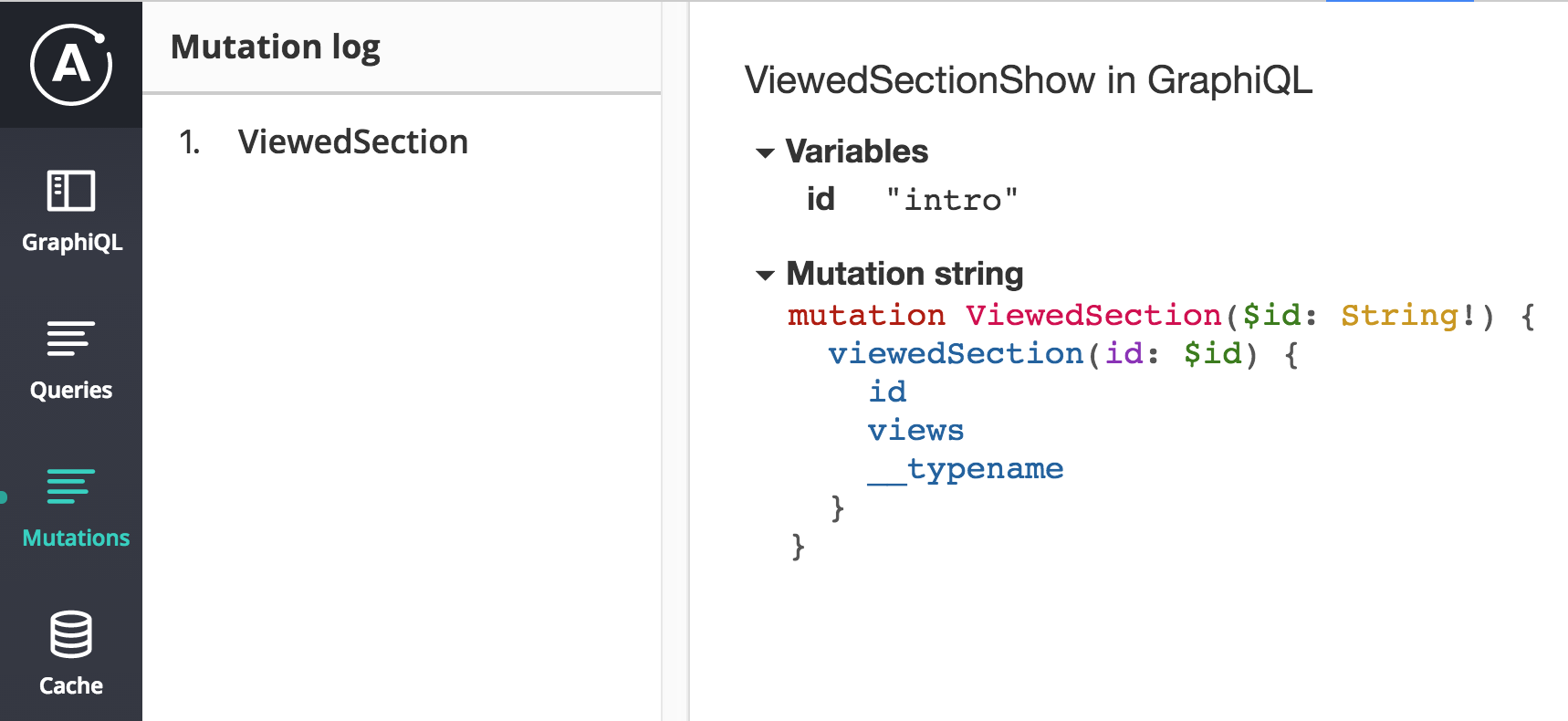
Under the Cache tab, we see the current state of the cache. Normalized data objects (any objects for which the id was requested) are listed on the left and appear in expandable <details> nodes on the right: